11.1 Portfolio Optimization¶
In this section the Markowitz portfolio optimization problem and variants are implemented using Fusion API for C++.
11.1.1 The Basic Model¶
The classical Markowitz portfolio optimization problem considers investing in \(n\) stocks or assets held over a period of time. Let \(x_j\) denote the amount invested in asset \(j\), and assume a stochastic model where the return of the assets is a random variable \(r\) with known mean
and covariance
The return of the investment is also a random variable \(y = r^Tx\) with mean (or expected return)
and variance
The standard deviation
is usually associated with risk.
The problem facing the investor is to rebalance the portfolio to achieve a good compromise between risk and expected return, e.g., maximize the expected return subject to a budget constraint and an upper bound (denoted \(\gamma\)) on the tolerable risk. This leads to the optimization problem
The variables \(x\) denote the investment i.e. \(x_j\) is the amount invested in asset \(j\) and \(x_j^0\) is the initial holding of asset \(j\). Finally, \(w\) is the initial amount of cash available.
A popular choice is \(x^0=0\) and \(w=1\) because then \(x_j\) may be interpreted as the relative amount of the total portfolio that is invested in asset \(j\).
Since \(e\) is the vector of all ones then
is the total investment. Clearly, the total amount invested must be equal to the initial wealth, which is
\[w + e^T x^0.\]
This leads to the first constraint
\[e^T x = w + e^T x^0.\]
The second constraint
\[x^T \Sigma x \leq \gamma^2\]
ensures that the variance, is bounded by the parameter \(\gamma^2\). Therefore, \(\gamma\) specifies an upper bound of the standard deviation (risk) the investor is willing to undertake. Finally, the constraint
\[x_j \geq 0\]
excludes the possibility of short-selling. This constraint can of course be excluded if short-selling is allowed.
The covariance matrix \(\Sigma\) is positive semidefinite by definition and therefore there exist a matrix \(G \in \mathbb{R}^{n\times k}\) such that
In general the choice of \(G\) is not unique and one possible choice of \(G\) is the Cholesky factorization of \(\Sigma\). However, in many cases another choice is better for efficiency reasons as discussed in Sec. 11.1.3 (Factor model and efficiency). For a given \(G\) we have that
Hence, we may write the risk constraint as
or equivalently
where \(\Q^{k+1}\) is the \((k+1)\)-dimensional quadratic cone. Note that specifically when \(G\) is derived using Cholesky factorization, \(k = n\).
Therefore, problem (11.1) can be written as
which is a conic quadratic optimization problem that can easily be formulated and solved with Fusion API for C++. Subsequently we will use the example data
and
Using Cholesky factorization, this implies
In Sec. 11.1.3 (Factor model and efficiency), we present a different way of obtaining \(G\) based on a factor model, that leads to more efficient computation.
Why a Conic Formulation?
Problem (11.1) is a convex quadratically constrained optimization problem that can be solved directly using MOSEK. Why then reformulate it as a conic quadratic optimization problem (11.3)? The main reason for choosing a conic model is that it is more robust and usually solves faster and more reliably. For instance it is not always easy to numerically validate that the matrix \(\Sigma\) in (11.1) is positive semidefinite due to the presence of rounding errors. It is also very easy to make a mistake so \(\Sigma\) becomes indefinite. These problems are completely eliminated in the conic formulation.
Moreover, observe the constraint
more numerically robust than
for very small and very large values of \(\gamma\). Indeed, if say \(\gamma \approx 10^4\) then \(\gamma^2\approx 10^8\), which introduces a scaling issue in the model. Hence, using conic formulation we work with the standard deviation instead of variance, which usually gives rise to a better scaled model.
Example code
Listing 11.1 demonstrates how the basic Markowitz model (11.3) is implemented.
double BasicMarkowitz
( int n,
std::shared_ptr<ndarray<double, 1>> mu,
std::shared_ptr<ndarray<double, 2>> GT,
std::shared_ptr<ndarray<double, 1>> x0,
double w,
double gamma)
{
Model::t M = new Model("Basic Markowitz"); auto _M = finally([&]() { M->dispose(); });
// Redirect log output from the solver to stdout for debugging.
// M->setLogHandler([](const std::string & msg) { std::cout << msg << std::flush; } );
// Defines the variables (holdings). Shortselling is not allowed.
Variable::t x = M->variable("x", n, Domain::greaterThan(0.0));
// Maximize expected return
M->objective("obj", ObjectiveSense::Maximize, Expr::dot(mu, x));
// The amount invested must be identical to intial wealth
M->constraint("budget", Expr::sum(x), Domain::equalsTo(w + sum(x0)));
// Imposes a bound on the risk
M->constraint("risk", Expr::vstack(gamma, Expr::mul(GT, x)), Domain::inQCone());
// Solves the model.
M->solve();
// Check if the solution is an optimal point
SolutionStatus solsta = M->getPrimalSolutionStatus();
if (solsta != SolutionStatus::Optimal)
{
// See https://docs.mosek.com/latest/cxxfusion/accessing-solution.html about handling solution statuses.
std::ostringstream oss;
oss << "Unexpected solution status: " << solsta << std::endl;
throw SolutionError(oss.str());
}
return dot(mu, x->level());
}
The source code should be self-explanatory except perhaps for
M->constraint("risk", Expr::vstack(gamma, Expr::mul(GT, x)), Domain::inQCone());
where the linear expression
is created using the Expr.vstack operator. Finally, the linear expression must lie in a quadratic cone implying
11.1.2 The Efficient Frontier¶
The portfolio computed by the Markowitz model is efficient in the sense that there is no other portfolio giving a strictly higher return for the same amount of risk. An efficient portfolio is also sometimes called a Pareto optimal portfolio. Clearly, an investor should only invest in efficient portfolios and therefore it may be relevant to present the investor with all efficient portfolios so the investor can choose the portfolio that has the desired tradeoff between return and risk.
Given a nonnegative \(\alpha\) the problem
is one standard way to trade the expected return against penalizing variance. Note that, in contrast to the previous example, we explicitly use the variance (\(\|G^Tx\|_2^2\)) rather than standard deviation (\(\|G^Tx\|_2\)), therefore the conic model includes a rotated quadratic cone:
The parameter \(\alpha\) specifies the tradeoff between expected return and variance. Ideally the problem (11.4) should be solved for all values \(\alpha \geq 0\) but in practice it is impossible. Using the example data from Sec. 11.1.1 (The Basic Model), the optimal values of return and variance for several values of \(\alpha\) are shown in the figure.
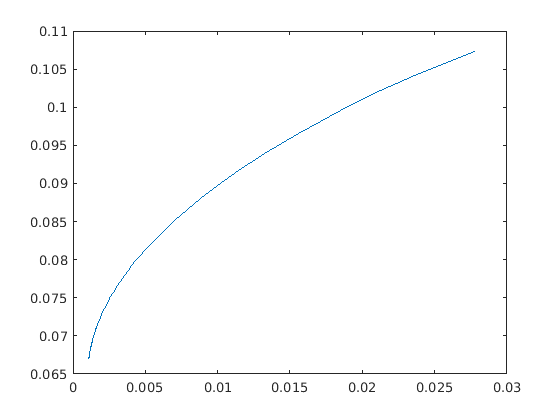
Fig. 11.1 The efficient frontier for the sample data.¶
Example code
Listing 11.2 demonstrates how to compute the efficient portfolios for several values of \(\alpha\).
here to download.¶void EfficientFrontier
( int n,
std::shared_ptr<ndarray<double, 1>> mu,
std::shared_ptr<ndarray<double, 2>> GT,
std::shared_ptr<ndarray<double, 1>> x0,
double w,
std::vector<double> & alphas,
std::vector<double> & frontier_mux,
std::vector<double> & frontier_s)
{
Model::t M = new Model("Efficient frontier"); auto M_ = finally([&]() { M->dispose(); });
// Defines the variables (holdings). Shortselling is not allowed.
Variable::t x = M->variable("x", n, Domain::greaterThan(0.0)); // Portfolio variables
Variable::t s = M->variable("s", 1, Domain::unbounded()); // Variance variable
M->constraint("budget", Expr::sum(x), Domain::equalsTo(w + sum(x0)));
// Computes the risk
M->constraint("variance", Expr::vstack(s, 0.5, Expr::mul(GT, x)), Domain::inRotatedQCone());
// Define objective as a weighted combination of return and variance
Parameter::t alpha = M->parameter();
M->objective("obj", ObjectiveSense::Maximize, Expr::sub(Expr::dot(mu, x), Expr::mul(alpha, s)));
// Solve the same problem for many values of parameter alpha
for (double a : alphas) {
alpha->setValue(a);
M->solve();
// Check if the solution is an optimal point
SolutionStatus solsta = M->getPrimalSolutionStatus();
if (solsta != SolutionStatus::Optimal)
{
// See https://docs.mosek.com/latest/cxxfusion/accessing-solution.html about handling solution statuses.
std::ostringstream oss;
oss << "Unexpected solution status: " << solsta << std::endl;
throw SolutionError(oss.str());
}
frontier_mux.push_back(dot(mu, x->level()));
frontier_s.push_back((*s->level())[0]);
}
}
Note that we defined \(\alpha\) as a model parameter and used it to parametrize the objective. This way we were able to reuse the same model for all solves along the efficient frontier, simply changing the value of \(\alpha\) between the solves.
11.1.3 Factor model and efficiency¶
In practice it is often important to solve the portfolio problem very quickly. Therefore, in this section we discuss how to improve computational efficiency at the modeling stage.
The computational cost is of course to some extent dependent on the number of constraints and variables in the optimization problem. However, in practice a more important factor is the sparsity: the number of nonzeros used to represent the problem. Indeed it is often better to focus on the number of nonzeros in \(G\) see (11.2) and try to reduce that number by for instance changing the choice of \(G\).
In other words if the computational efficiency should be improved then it is always good idea to start with focusing at the covariance matrix. As an example assume that
where \(D\) is a positive definite diagonal matrix. Moreover, \(V\) is a matrix with \(n\) rows and \(k\) columns. Such a model for the covariance matrix is called a factor model and usually \(k\) is much smaller than \(n\). In practice \(k\) tends to be a small number independent of \(n\), say less than 100.
One possible choice for \(G\) is the Cholesky factorization of \(\Sigma\) which requires storage proportional to \(n(n+1)/2\). However, another choice is
because then
This choice requires storage proportional to \(n+kn\) which is much less than for the Cholesky choice of \(G\). Indeed assuming \(k\) is a constant storage requirements are reduced by a factor of \(n\).
The example above exploits the so-called factor structure and demonstrates that an alternative choice of \(G\) may lead to a significant reduction in the amount of storage used to represent the problem. This will in most cases also lead to a significant reduction in the solution time.
The lesson to be learned is that it is important to investigate how the covariance matrix is formed. Given this knowledge it might be possible to make a special choice for \(G\) that helps reducing the storage requirements and enhance the computational efficiency. More details about this process can be found in [And13].
Factor model in finance
Factor model structure is typical in financial context. It is common to model security returns as the sum of two components using a factor model. The first component is the linear combination of a small number of factors common among a group of securities. The second component is a residual, specific to each security. It can be written as \(R = \sum_j\beta_j F_j + \theta\), where \(R\) is a random variable representing the return of a security at a particular point in time, \(F_j\) is the random variable representing the common factor \(j\), \(\beta_j\) is the exposure of the return to factor \(j\), and \(\theta\) is the specific component.
Such a model will result in the covariance structure
where \(\Sigma_F\) is the covariance of the factors and \(\Sigma_\theta\) is the residual covariance. This structure is of the form discussed earlier with \(D = \Sigma_\theta\) and \(V = \beta P\), assuming the decomposition \(\Sigma_F = PP^T\). If the number of factors \(k\) is low and \(\Sigma_\theta\) is diagonal, we get a very sparse \(G\) that provides the storage and solution time benefits.
Example code
Here we will work with the example data of a two-factor model (\(k=2\)) built using the variables
and the factor covariance matrix is
giving
Then the matrix \(G\) would look like
This matrix is indeed very sparse.
In general, we get an \(n\times (n+k)\) size matrix this way with \(k\) full columns and an \(n\times n\) diagonal part. In order to maintain a sparse representation we do not construct the matrix \(G\) explicitly in the code but instead work with two pieces of data: the dense matrix \(G_\mathrm{factor} = \beta P\) of shape \(n\times k\) and the diagonal vector \(\theta\) of length \(n\).
Example code
In the following we demonstrate how to write code to compute the matrix \(G_\mathrm{factor}\) of the factor model. We start with the inputs
// Factor exposure matrix
auto B = new_array_ptr<double, 2>({
{0.4256, 0.1869},
{0.2413, 0.3877},
{0.2235, 0.3697},
{0.1503, 0.4612},
{1.5325, -0.2633},
{1.2741, -0.2613},
{0.6939, 0.2372},
{0.5425, 0.2116}
});
// Factor covariance matrix
auto S_F = new_array_ptr<double, 2>({
{0.0620, 0.0577},
{0.0577, 0.0908}
});
// Specific risk components
auto theta = new_array_ptr<double, 1>({0.0720, 0.0508, 0.0377, 0.0394, 0.0663, 0.0224, 0.0417, 0.0459});
Then the matrix \(G_\mathrm{factor}\) is obtained as:
auto P = cholesky(S_F);
auto G_factor = matrix_mul(B, P);
auto G_factor_T = transpose(G_factor);
The functions used above to operate on matrices are defined in the source file that can be downloaded from Listing 11.3.
The code for computing an optimal portfolio in the factor model is very similar to the one from the basic model in Listing 11.1 with one notable exception: we construct the expression \(G^Tx\) appearing in the conic constraint by stacking together two separate vectors \(G_\mathrm{factor}^T x\) and \(\Sigma^{1/2}_\theta x\):
// Imposes a bound on the risk
M->constraint("risk", Expr::vstack(new_array_ptr<Expression::t, 1>({Expr::constTerm(gamma),
Expr::mul(G_factor_T, x),
Expr::mulElm(vector_sqrt(theta), x)})), Domain::inQCone());
The full code is demonstrated below:
double FactorMarkowitz(
int n,
farray<double, 1> mu,
farray<double, 2> G_factor_T,
farray<double, 1> theta,
farray<double, 1> x0,
double w,
double gamma
)
{
Model::t M = new Model("Factor Markowitz"); auto _M = finally([&]() { M->dispose(); });
// Redirect log output from the solver to stdout for debugging.
// M->setLogHandler([](const std::string & msg) { std::cout << msg << std::flush; } );
// Defines the variables (holdings). Shortselling is not allowed.
Variable::t x = M->variable("x", n, Domain::greaterThan(0.0));
// Maximize expected return
M->objective("obj", ObjectiveSense::Maximize, Expr::dot(mu, x));
// The amount invested must be identical to intial wealth
M->constraint("budget", Expr::sum(x), Domain::equalsTo(w + sum(x0)));
// Imposes a bound on the risk
M->constraint("risk", Expr::vstack(new_array_ptr<Expression::t, 1>({Expr::constTerm(gamma),
Expr::mul(G_factor_T, x),
Expr::mulElm(vector_sqrt(theta), x)})), Domain::inQCone());
// Solves the model.
M->solve();
// Check if the solution is an optimal point
SolutionStatus solsta = M->getPrimalSolutionStatus();
if (solsta != SolutionStatus::Optimal)
{
// See https://docs.mosek.com/latest/cxxfusion/accessing-solution.html about handling solution statuses.
std::ostringstream oss;
oss << "Unexpected solution status: " << solsta << std::endl;
throw SolutionError(oss.str());
}
return dot(mu, x->level());
}
11.1.4 Slippage Cost¶
The basic Markowitz model assumes that there are no costs associated with trading the assets and that the returns of the assets are independent of the amount traded. Neither of those assumptions is usually valid in practice. Therefore, a more realistic model is
Here \(\Delta x_j\) is the change in the holding of asset \(j\) i.e.
and \(T_j(\Delta x_j)\) specifies the transaction costs when the holding of asset \(j\) is changed from its initial value. In the next two sections we show two different variants of this problem with two nonlinear cost functions \(T\).
11.1.5 Market Impact Costs¶
If the initial wealth is fairly small and no short selling is allowed, then the holdings will be small and the traded amount of each asset must also be small. Therefore, it is reasonable to assume that the prices of the assets are independent of the amount traded. However, if a large volume of an asset is sold or purchased, the price, and hence return, can be expected to change. This effect is called market impact costs. It is common to assume that the market impact cost for asset \(j\) can be modeled by
where \(m_j\) is a constant that is estimated in some way by the trader. See [GK00] [p. 452] for details. From the Modeling Cookbook we know that \(t \geq |z|^{3/2}\) can be modeled directly using the power cone \(\POW_3^{2/3,1/3}\):
Hence, it follows that \(\sum_{j=1}^n T_j(\Delta x_j)=\sum_{j=1}^n m_j|x_j-x_j^0|^{3/2}\) can be modeled by \(\sum_{j=1}^n m_jt_j\) under the constraints
Unfortunately this set of constraints is nonconvex due to the constraint
but in many cases the constraint may be replaced by the relaxed constraint
For instance if the universe of assets contains a risk free asset then
cannot hold for an optimal solution.
If the optimal solution has the property (11.9) then the market impact cost within the model is larger than the true market impact cost and hence money are essentially considered garbage and removed by generating transaction costs. This may happen if a portfolio with very small risk is requested because the only way to obtain a small risk is to get rid of some of the assets by generating transaction costs. We generally assume that this is not the case and hence the models (11.7) and (11.8) are equivalent.
The above observations lead to
The revised budget constraint
specifies that the initial wealth covers the investment and the transaction costs. It should be mentioned that transaction costs of the form
where \(p>1\) is a real number can be modeled with the power cone as
See the Modeling Cookbook for details.
Example code
Listing 11.5 demonstrates how to compute an optimal portfolio when market impact cost are included.
void MarkowitzWithMarketImpact
( int n,
std::shared_ptr<ndarray<double, 1>> mu,
std::shared_ptr<ndarray<double, 2>> GT,
std::shared_ptr<ndarray<double, 1>> x0,
double w,
double gamma,
std::shared_ptr<ndarray<double, 1>> m,
std::vector<double> & xsol,
std::vector<double> & tsol)
{
Model::t M = new Model("Markowitz portfolio with market impact"); auto M_ = finally([&]() { M->dispose(); });
// Defines the variables. No shortselling is allowed.
Variable::t x = M->variable("x", n, Domain::greaterThan(0.0));
// Variables computing the impact cost
Variable::t t = M->variable("t", n, Domain::unbounded());
// Maximize expected return
M->objective("obj", ObjectiveSense::Maximize, Expr::dot(mu, x));
// Invested amount + slippage cost = initial wealth
M->constraint("budget", Expr::add(Expr::sum(x), Expr::dot(m, t)), Domain::equalsTo(w + sum(x0)));
// Imposes a bound on the risk
M->constraint("risk", Expr::vstack( gamma, Expr::mul(GT, x)),
Domain::inQCone());
// t >= |x-x0|^1.5, using a power cone
M->constraint("tz", Expr::hstack(t, Expr::constTerm(n, 1.0), Expr::sub(x, x0)), Domain::inPPowerCone(2.0/3.0));
M->solve();
// Check if the solution is an optimal point
SolutionStatus solsta = M->getPrimalSolutionStatus();
if (solsta != SolutionStatus::Optimal)
{
// See https://docs.mosek.com/latest/cxxfusion/accessing-solution.html about handling solution statuses.
std::ostringstream oss;
oss << "Unexpected solution status: " << solsta << std::endl;
throw SolutionError(oss.str());
}
xsol.resize(n);
tsol.resize(n);
auto xlvl = x->level();
auto tlvl = t->level();
std::copy(xlvl->flat_begin(), xlvl->flat_end(), xsol.begin());
std::copy(tlvl->flat_begin(), tlvl->flat_end(), tsol.begin());
}
If the market impact cost uses different exponents for different assets then they can still be added in one vectorized block by using Domain.inPPowerConeSeq.
11.1.6 Transaction Costs¶
Now assume there is a cost associated with trading asset \(j\) given by
Hence, whenever asset \(j\) is traded we pay a fixed setup cost \(f_j\) and a variable cost of \(g_j\) per unit traded. Given the assumptions about transaction costs in this section problem (11.6) may be formulated as
(11.11)¶\[\begin{split}\begin{array}{lrcll} \mbox{maximize} & \mu^T x & & &\\ \mbox{subject to} & e^T x + f^Ty + g^T z & = & w + e^T x^0, &\\ & (\gamma,G^T x) & \in & \Q^{k+1}, & \\ & z_j & \geq & x_j - x_j^0, & j=1,\ldots,n,\\ & z_j & \geq & x_j^0 - x_j, & j=1,\ldots,n,\\ & z_j & \leq & U_j y_j, & j=1,\ldots,n,\\ & y_j & \in & \{0,1\}, & j=1,\ldots,n, \\ & x & \geq & 0. & \end{array}\end{split}\]
First observe that
We choose \(U_j\) as some a priori upper bound on the amount of trading in asset \(j\) and therefore if \(z_j>0\) then \(y_j = 1\) has to be the case. This implies that the transaction cost for asset \(j\) is given by
Example code
The following example code demonstrates how to compute an optimal portfolio when transaction costs are included.
std::shared_ptr<ndarray<double, 1>> MarkowitzWithTransactionsCost
( int n,
std::shared_ptr<ndarray<double, 1>> mu,
std::shared_ptr<ndarray<double, 2>> GT,
std::shared_ptr<ndarray<double, 1>> x0,
double w,
double gamma,
std::shared_ptr<ndarray<double, 1>> f,
std::shared_ptr<ndarray<double, 1>> g)
{
// Upper bound on the traded amount
std::shared_ptr<ndarray<double, 1>> u(new ndarray<double, 1>(shape_t<1>(n), w + sum(x0)));
Model::t M = new Model("Markowitz portfolio with transaction costs"); auto M_ = finally([&]() { M->dispose(); });
// Defines the variables. No shortselling is allowed.
Variable::t x = M->variable("x", n, Domain::greaterThan(0.0));
// Addtional "helper" variables
Variable::t z = M->variable("z", n, Domain::unbounded());
// Binary varables
Variable::t y = M->variable("y", n, Domain::binary());
// Maximize expected return
M->objective("obj", ObjectiveSense::Maximize, Expr::dot(mu, x));
// Invest amount + transactions costs = initial wealth
M->constraint("budget", Expr::add(Expr::add(Expr::sum(x), Expr::dot(f, y)), Expr::dot(g, z)),
Domain::equalsTo(w + sum(x0)));
// Imposes a bound on the risk
M->constraint("risk", Expr::vstack( gamma, Expr::mul(GT, x)),
Domain::inQCone());
// z >= |x-x0|
M->constraint("buy", Expr::sub(z, Expr::sub(x, x0)), Domain::greaterThan(0.0));
M->constraint("sell", Expr::sub(z, Expr::sub(x0, x)), Domain::greaterThan(0.0));
// Consraints for turning y off and on. z-diag(u)*y<=0 i.e. z_j <= u_j*y_j
M->constraint("y_on_off", Expr::sub(z, Expr::mul(Matrix::diag(u), y)), Domain::lessThan(0.0));
// Integer optimization problems can be very hard to solve so limiting the
// maximum amount of time is a valuable safe guard
M->setSolverParam("mioMaxTime", 180.0);
M->solve();
// Check if the solution is an optimal point
SolutionStatus solsta = M->getPrimalSolutionStatus();
if (solsta != SolutionStatus::Optimal)
{
// See https://docs.mosek.com/latest/cxxfusion/accessing-solution.html about handling solution statuses.
std::ostringstream oss;
oss << "Unexpected solution status: " << solsta << std::endl;
throw SolutionError(oss.str());
}
return x->level();
}
11.1.7 Cardinality constraints¶
Another method to reduce costs involved with processing transactions is to only change positions in a small number of assets. In other words, at most \(K\) of the differences \(|\Delta x_j|=|x_j - x_j^0|\) are allowed to be non-zero, where \(K\) is (much) smaller than the total number of assets \(n\).
This type of constraint can be again modeled by introducing a binary variable \(y_j\) which indicates if \(\Delta x_j\neq 0\) and bounding the sum of \(y_j\). The basic Markowitz model then gets updated as follows:
(11.12)¶\[\begin{split}\begin{array}{lrcll} \mbox{maximize} & \mu^T x & & &\\ \mbox{subject to} & e^T x & = & w + e^T x^0, &\\ & (\gamma,G^T x) & \in & \Q^{k+1}, & \\ & z_j & \geq & x_j - x_j^0, & j=1,\ldots,n,\\ & z_j & \geq & x_j^0 - x_j, & j=1,\ldots,n,\\ & z_j & \leq & U_j y_j, & j=1,\ldots,n,\\ & y_j & \in & \{0,1\}, & j=1,\ldots,n, \\ & e^T y & \leq & K, & \\ & x & \geq & 0, & \end{array}\end{split}\]
were \(U_j\) is some a priori chosen upper bound on the amount of trading in asset \(j\).
Example code
The following example code demonstrates how to compute an optimal portfolio with cardinality bounds. Note that we define the maximum cardinality as a parameter in the model and use it to parametrize the cardinality constraint. This way we can use one model to solve many problems with the same structure and data except for the cardinality bound by simply changing this parameter between the solves.
std::vector<std::vector<double>> MarkowitzWithCardinality
( int n,
std::shared_ptr<ndarray<double, 1>> mu,
std::shared_ptr<ndarray<double, 2>> GT,
std::shared_ptr<ndarray<double, 1>> x0,
double w,
double gamma,
std::vector<int> kValues)
{
// Upper bound on the traded amount
std::shared_ptr<ndarray<double, 1>> u(new ndarray<double, 1>(shape_t<1>(n), w + sum(x0)));
Model::t M = new Model("Markowitz portfolio with cardinality constraints"); auto M_ = finally([&]() { M->dispose(); });
// Defines the variables. No shortselling is allowed.
Variable::t x = M->variable("x", n, Domain::greaterThan(0.0));
// Addtional "helper" variables
Variable::t z = M->variable("z", n, Domain::unbounded());
// Binary varables
Variable::t y = M->variable("y", n, Domain::binary());
// Maximize expected return
M->objective("obj", ObjectiveSense::Maximize, Expr::dot(mu, x));
// The amount invested must be identical to initial wealth
M->constraint("budget", Expr::sum(x), Domain::equalsTo(w + sum(x0)));
// Imposes a bound on the risk
M->constraint("risk", Expr::vstack( gamma, Expr::mul(GT, x)),
Domain::inQCone());
// z >= |x-x0|
M->constraint("buy", Expr::sub(z, Expr::sub(x, x0)), Domain::greaterThan(0.0));
M->constraint("sell", Expr::sub(z, Expr::sub(x0, x)), Domain::greaterThan(0.0));
// Consraints for turning y off and on. z-diag(u)*y<=0 i.e. z_j <= u_j*y_j
M->constraint("y_on_off", Expr::sub(z, Expr::mul(Matrix::diag(u), y)), Domain::lessThan(0.0));
// At most k assets change position
auto cardMax = M->parameter();
M->constraint("cardinality", Expr::sub(Expr::sum(y), cardMax), Domain::lessThan(0));
// Integer optimization problems can be very hard to solve so limiting the
// maximum amount of time is a valuable safe guard
M->setSolverParam("mioMaxTime", 180.0);
// Solve multiple instances by varying the cardinality bound
std::vector<std::vector<double>> results;
for(auto k : kValues) {
cardMax->setValue(k);
M->solve();
// Check if the solution is an optimal point
SolutionStatus solsta = M->getPrimalSolutionStatus();
if (solsta != SolutionStatus::Optimal)
{
// See https://docs.mosek.com/latest/cxxfusion/accessing-solution.html about handling solution statuses.
std::ostringstream oss;
oss << "Unexpected solution status: " << solsta << std::endl;
throw SolutionError(oss.str());
}
auto sol = x->level();
results.push_back(new_vector_from_array_ptr(sol));
}
return results;
}
If we solve our running example with \(K=1,\dots,n\) then we get the following solutions, with increasing expected returns:
Bound 1 Solution: 0.0000e+00 0.0000e+00 1.0000e+00 0.0000e+00 0.0000e+00 0.0000e+00 0.0000e+00 0.0000e+00
Bound 2 Solution: 0.0000e+00 0.0000e+00 3.5691e-01 0.0000e+00 0.0000e+00 6.4309e-01 -0.0000e+00 0.0000e+00
Bound 3 Solution: 0.0000e+00 0.0000e+00 1.9258e-01 0.0000e+00 0.0000e+00 5.4592e-01 2.6150e-01 0.0000e+00
Bound 4 Solution: 0.0000e+00 0.0000e+00 2.0391e-01 0.0000e+00 6.7098e-02 4.9181e-01 2.3718e-01 0.0000e+00
Bound 5 Solution: 0.0000e+00 3.1970e-02 1.7028e-01 0.0000e+00 7.0741e-02 4.9551e-01 2.3150e-01 0.0000e+00
Bound 6 Solution: 0.0000e+00 3.1970e-02 1.7028e-01 0.0000e+00 7.0740e-02 4.9551e-01 2.3150e-01 0.0000e+00
Bound 7 Solution: 0.0000e+00 3.1970e-02 1.7028e-01 0.0000e+00 7.0740e-02 4.9551e-01 2.3150e-01 0.0000e+00
Bound 8 Solution: 1.9557e-10 2.6992e-02 1.6706e-01 2.9676e-10 7.1245e-02 4.9559e-01 2.2943e-01 9.6905e-03
