6 Semidefinite optimization¶
In this chapter we extend the conic optimization framework introduced before with symmetric positive semidefinite matrix variables.
6.1 Introduction to semidefinite matrices¶
6.1.1 Semidefinite matrices and cones¶
A symmetric matrix \(X\in \mathcal{S}^n\) is called symmetric positive semidefinite if
We then define the cone of symmetric positive semidefinite matrices as
For brevity we will often use the shorter notion semidefinite instead of symmetric positive semidefinite, and we will write \(X\succeq Y\) (\(X \preceq Y\)) as shorthand notation for \((X-Y)\in \PSD^n\) (\((Y-X)\in \PSD^n\)). As inner product for semidefinite matrices, we use the standard trace inner product for general matrices, i.e.,
It is easy to see that (6.1) indeed specifies a convex cone; it is pointed (with origin \(X=0\)), and \(X,Y\in \PSD^n\) implies that \((\alpha X + \beta Y)\in \PSD^n, \: \alpha,\beta \geq 0\). Let us review a few equivalent definitions of \(\PSD^n\). It is well-known that every symmetric matrix \(A\) has a spectral factorization
where \(q_i \in \mathbb{R}^n\) are the (orthogonal) eigenvectors and \(\lambda_i\) are eigenvalues of \(A\). Using the spectral factorization of \(A\) we have
which shows that \(x^T A x \geq 0 \: \Leftrightarrow \: \lambda_i \geq 0, \: i=1,\dots,n\). In other words,
Another useful characterization is that \(A\in \PSD^n\) if and only if it is a Grammian matrix \(A=V^T V\). Here \(V\) is called the Cholesky factor of \(A\). Using the Grammian representation we have
i.e., if \(A=V^TV\) then \(x^T A x \geq 0\) for all \(x\). On the other hand, from the positive spectral factorization \(A=Q\Lambda Q^T\) we have \(A = V^T V\) with \(V=\Lambda^{1/2} Q^T\), where \(\Lambda^{1/2}=\Diag(\sqrt{\lambda_1}, \ldots, \sqrt{\lambda_n})\). We thus have the equivalent characterization
In a completely analogous way we define the cone of symmetric positive definite matrices as
and we write \(X\succ Y\) (\(X\prec Y\)) as shorthand notation for \((X-Y)\in \PD^n\) (\((Y-X)\in \PD^n\)).
The one dimensional cone \(\PSD^1\) simply corresponds to \(\R_+\). Similarly consider
with determinant \(\det(X)=x_1 x_2 - x_3^2 = \lambda_1\lambda_2\) and trace \(\mathrm{tr}(X)=x_1 + x_2 = \lambda_1 + \lambda_2\). Therefore \(X\) has positive eigenvalues if and only if
which characterizes a three-dimensional scaled rotated cone, i.e.,
More generally we have
and
where the latter equivalence follows immediately from Lemma 6.1. Thus both the linear and quadratic cone are embedded in the semidefinite cone. In practice, however, linear and quadratic cones should never be described using semidefinite constraints, which would result in a large performance penalty by squaring the number of variables.
As a more interesting example, consider the symmetric matrix
parametrized by \((x,y,z)\). The set
(shown in Fig. 6.1) is called a spectrahedron and is perhaps the simplest bounded semidefinite representable set, which cannot be represented using (finitely many) linear or quadratic cones. To gain a geometric intuition of \(S\), we note that
so the boundary of \(S\) can be characterized as
or equivalently as
For \(z=0\) this describes a circle in the \((x,y)\)-plane, and for \(-1\leq z \leq 1\) it characterizes an ellipse (for a fixed \(z\)).

Fig. 6.1 Plot of spectrahedron \(S=\{ (x,y,z) \in \R^3 \mid A(x,y,z)\succeq 0 \}\).¶
6.1.2 Properties of semidefinite matrices¶
Many useful properties of (semi)definite matrices follow directly from the definitions (6.1)-(6.4) and their definite counterparts.
The diagonal elements of \(A\in\PSD^n\) are nonnegative. Let \(e_i\) denote the \(i\)th standard basis vector (i.e., \([e_i]_j=0,\: j\neq i\), \([e_i]_i=1\)). Then \(A_{ii}=e_i^T A e_i\), so (6.1) implies that \(A_{ii}\geq 0\).
A block-diagonal matrix \(A=\Diag(A_1,\dots A_p)\) is (semi)definite if and only if each diagonal block \(A_i\) is (semi)definite.
Given a quadratic transformation \(M:=B^T A B\), \(M\succ 0\) if and only if \(A\succ 0\) and \(B\) has full rank. This follows directly from the Grammian characterization \(M=(VB)^T(VB)\). For \(M\succeq 0\) we only require that \(A\succeq 0\). As an example, if \(A\) is (semi)definite then so is any permutation \(P^T A P\).
Any principal submatrix of \(A\in \PSD^n\) (\(A\) restricted to the same set of rows as columns) is positive semidefinite; this follows by restricting the Grammian characterization \(A=V^T V\) to a submatrix of \(V\).
The inner product of positive (semi)definite matrices is positive (nonnegative). For any \(A,B\in \PD^n\) let \(A=U^TU\) and \(B=V^T V\) where \(U\) and \(V\) have full rank. Then
\[\langle A, B \rangle = \mathrm{tr}(U^T U V^T V) = \|U V^T \|_F^2 > 0,\]where strict positivity follows from the assumption that \(U\) has full column-rank, i.e., \(UV^T \neq 0\).
The inverse of a positive definite matrix is positive definite. This follows from the positive spectral factorization \(A=Q \Lambda Q^T\), which gives us
\[A^{-1} = Q^T \Lambda^{-1} Q\]where \(\Lambda_{ii}>0\). If \(A\) is semidefinite then the pseudo-inverse \(A^\dagger\) of \(A\) is semidefinite.
Consider a matrix \(X\in\Symm^n\) partitioned as
\[\begin{split}X = \left[\begin{array}{cc} A & B^T\\ B & C \end{array}\right].\end{split}\]Let us find necessary and sufficient conditions for \(X\succ 0\). We know that \(A\succ 0\) and \(C\succ 0\) (since any principal submatrix must be positive definite). Furthermore, we can simplify the analysis using a nonsingular transformation
\[\begin{split}L = \left[\begin{array}{cc} I & 0\\ F & I \end{array}\right]\end{split}\]to diagonalize \(X\) as \(L X L^T = D\), where \(D\) is block-diagonal. Note that \(\det(L)=1\), so \(L\) is indeed nonsingular. Then \(X\succ 0\) if and only if \(D\succ 0\). Expanding \(L X L^T = D\), we get
\[\begin{split}\left[\begin{array}{cc} A & AF^T + B^T\\ FA + B & F A F^T + F B^T + B F^T + C \end{array}\right] = \left[\begin{array}{cc} D_1 & 0\\ 0 & D_2 \end{array}\right].\end{split}\]Since \(\det(A)\neq 0\) (by assuming that \(A\succ 0\)) we see that \(F=-BA^{-1}\) and direct substitution gives us
\[\begin{split}\left[\begin{array}{cc} A & 0\\ 0 & C - B A^{-1} B^T \end{array}\right] = \left[\begin{array}{cc} D_1 & 0\\ 0 & D_2 \end{array}\right].\end{split}\]
In the last part we have thus established the following useful result.
A symmetric matrix
is positive definite if and only if
6.2 Semidefinite modeling¶
Having discussed different characterizations and properties of semidefinite matrices, we next turn to different functions and sets that can be modeled using semidefinite cones and variables. Most of those representations involve semidefinite matrix-valued affine functions, which we discuss next.
6.2.1 Linear matrix inequalities¶
Consider an affine matrix-valued mapping \(A:\R^n \mapsto \mathcal{S}^m\):
A linear matrix inequality (LMI) is a constraint of the form
in the variable \(x\in \R^n\) with symmetric coefficients \(A_i\in\mathcal{S}^m,\: i=0,\dots,n\). As a simple example consider the matrix in (6.5),
with
Alternatively, we can describe the linear matrix inequality \(A(x,y,z)\succeq 0\) as
i.e., as a semidefinite variable with fixed diagonal; these two alternative formulations illustrate the difference between primal and dual form of semidefinite problems, see Sec. 8.6 (Semidefinite duality and LMIs).
6.2.2 Eigenvalue optimization¶
Consider a symmetric matrix \(A\in \mathcal{S}^m\) and let its eigenvalues be denoted by
A number of different functions of \(\lambda_i\) can then be described using a mix of linear and semidefinite constraints.
Sum of eigenvalues
The sum of the eigenvalues corresponds to
Largest eigenvalue
The largest eigenvalue can be characterized in epigraph form \(\lambda_1(A)\leq t\) as
To verify this, suppose we have a spectral factorization \(A=Q \Lambda Q^T\) where \(Q\) is orthogonal and \(\Lambda\) is diagonal. Then \(t\) is an upper bound on the largest eigenvalue if and only if
Thus we can minimize the largest eigenvalue of \(A\).
Smallest eigenvalue
The smallest eigenvalue can be described in hypograph form \(\lambda_m(A) \geq t\) as
i.e., we can maximize the smallest eigenvalue of \(A\).
Eigenvalue spread
The eigenvalue spread can be modeled in epigraph form
by combining the two linear matrix inequalities in (6.10) and (6.11), i.e.,
Spectral radius
The spectral radius \(\rho(A):=\max_i |\lambda_i(A) |\) can be modeled in epigraph form \(\rho(A)\leq t\) using two linear matrix inequalities
Condition number of a positive definite matrix
Suppose now that \(A\in\PSD^m\). The condition number of a positive definite matrix can be minimized by noting that \(\lambda_1(A)/\lambda_m(A)\leq t\) if and only if there exists a \(\mu>0\) such that
or equivalently if and only if \(I \preceq \mu^{-1}A \preceq t I\). If \(A=A(x)\) is represented as in (6.8) then a change of variables \(z:=x/\mu\), \(\nu:=1/\mu\) leads to a problem of the form
from which we recover the solution \(x=z/\nu\). In essence, we first normalize the spectrum by the smallest eigenvalue, and then minimize the largest eigenvalue of the normalized linear matrix inequality. Compare Sec. 2.2.5 (Homogenization).
6.2.3 Log-determinant¶
Consider again a symmetric positive-definite matrix \(A\in\PSD^m\). The determinant
is neither convex or concave, but \(\log \det(A)\) is concave and we can write the inequality
in the form of the following problem:
The equivalence of the two problems follows from Lemma 6.1 and subadditivity of determinant for semidefinite matrices. That is:
On the other hand the optimal value \(\det(A)\) is attained for \(Z=LD\) if \(A=LDL^T\) is the LDL factorization of \(A\).
The last inequality in problem (6.13) can of course be modeled using the exponential cone as in Sec. 5.2 (Modeling with the exponential cone). Note that we can replace that bound with \(t\leq (\prod_i Z_{ii})^{1/m}\) to get instead the model of \(t\leq \det(A)^{1/m}\) using Sec. 4.2.4 (Geometric mean).
6.2.4 Singular value optimization¶
We next consider a non-square matrix \(A\in\R^{m\times p}\). Assume \(p\leq m\) and denote the singular values of \(A\) by
The singular values are connected to the eigenvalues of \(A^T A\) via
and if \(A\) is square and symmetric then \(\sigma_i(A)=|\lambda_i(A)|\). We show next how to optimize several functions of the singular values.
Largest singular value
The epigraph \(\sigma_1(A)\leq t\) can be characterized using (6.14) as
which from Schur’s lemma is equivalent to
The largest singular value \(\sigma_1(A)\) is also called the spectral norm or the \(\ell_2\)-norm of \(A\), \(\|A\|_2 := \sigma_1(A)\).
Sum of singular values
The trace norm or the nuclear norm of \(X\) is the dual of the \(\ell_2\)-norm:
It turns out that the nuclear norm corresponds to the sum of the singular values,
which is easy to verify using singular value decomposition \(X=U \Sigma V^T\). We have
which shows (6.17). Alternatively, we can express (6.16) as the solution to
with the dual problem (see Sec. 8.6.3 (Sum of singular values revisited))
In other words, using strong duality we can characterize the epigraph \(\| A \|_{*}\leq t\) with
For a symmetric matrix the nuclear norm corresponds to the sum of absolute values of eigenvalues, and for a semidefinite matrix it simply corresponds to the trace of the matrix.
6.2.5 Matrix inequalities from Schur’s Lemma¶
Several quadratic or quadratic-over-linear matrix inequalities follow immediately from Schur’s lemma. Suppose \(A\in \R^{m\times p}\) and \(B\in \R^{p\times p}\) are matrix variables. Then
if and only if
In robust control theory one encounters Riccati matrix inequalities
which are quadratic in the symmetric matrix variable \(P\). By Schur’s lemma this condition can be written as a linear matrix inequality
6.2.6 Nonnegative polynomials¶
We next consider characterizations of polynomials constrained to be nonnegative on the real axis. To that end, consider a polynomial basis function
It is then well-known that a polynomial \(f:\R\mapsto \R\) of even degree \(2n\) is nonnegative on the entire real axis
if and only if it can be written as a sum of squared polynomials of degree \(n\) (or less), i.e., for some \(q_1,q_2\in \R^{n+1}\)
It turns out that an equivalent characterization of \(\{ x \mid x^Tv(t)\geq 0, \: \forall t\}\) can be given in terms of a semidefinite variable \(X\),
where \(H^{n+1}_i\in \R^{(n+1)\times (n+1)}\) are Hankel matrices
When there is no ambiguity, we drop the superscript on \(H_i\). For example, for \(n=2\) we have
To verify that (6.21) and (6.23) are equivalent, we first note that
i.e.,
Assume next that \(f(t)\geq 0\). Then from (6.22) we have
i.e., we have \(f(t)=x^T v(t)\) with \(x_i = \langle X, H_i \rangle, \: X = (q_1q_1^T + q_2 q_2^T)\succeq 0\). Conversely, assume that (6.23) holds. Then
since \(X\succeq 0\). In summary, we can characterize the cone of nonnegative polynomials over the real axis as
Checking nonnegativity of a univariate polynomial thus corresponds to a semidefinite feasibility problem.
6.2.6.1 Nonnegativity on a finite interval¶
As an extension we consider a basis function of degree \(n\),
A polynomial \(f(t):=x^T v(t)\) is then nonnegative on a subinterval \(I=[a,b]\subset \R\) if and only \(f(t)\) can be written as a sum of weighted squares,
where \(w_i(t)\) are polynomials nonnegative on \([a,b]\). To describe the cone
we distinguish between polynomials of odd and even degree.
Even degree. Let \(n=2m\) and denote
\[u_1(t)=(1,t,\ldots,t^m), \qquad u_2(t)=(1,t,\ldots,t^{m-1}).\]We choose \(w_1(t)=1\) and \(w_2(t)=(t-a)(b-t)\) and note that \(w_2(t)\geq 0\) on \([a,b]\). Then \(f(t)\geq 0, \forall t\in [a, b]\) if and only if
\[f(t) = (q_1^T u_1(t))^2 + w_2(t)(q_2^T u_2(t))^2\]for some \(q_1, q_2\), and an equivalent semidefinite characterization can be found as
(6.25)¶\[\begin{split} K^n_{a,b} = \{ x\in \R^{n+1} \mid x_i = \langle X_1, H^m_i\rangle + \langle X_2, (a+b)H^{m-1}_{i-1}-ab H^{m-1}_i - H^{m-1}_{i-2}\rangle, \\ \, i=0,\ldots,n, \, X_1 \in \PSD^m, \, X_2 \in \PSD^{m-1} \}.\end{split}\]Odd degree. Let \(n=2m+1\) and denote \(u(t)=(1,t,\ldots,t^m)\). We choose \(w_1(t)=(t-a)\) and \(w_2(t)=(b-t)\). We then have that \(f(t)=x^T v(t)\geq 0, \forall t\in[a,b]\) if and only if
\[f(t) = (t-a)(q_1^T u(t))^2 + (b-t)(q_2^T u(t))^2\]for some \(q_1, q_2\), and an equivalent semidefinite characterization can be found as
(6.26)¶\[\begin{split}K^n_{a,b} = \{ x\in \R^{n+1} \mid x_i = \langle X_1, H^m_{i-1} - a H^m_i\rangle + \langle X_2, bH^m_i- H^m_{i-1}\rangle, \\ \, i=0,\ldots,n, \, X_1, X_2 \in \PSD^m \}.\end{split}\]
6.2.7 Hermitian matrices¶
Semidefinite optimization can be extended to complex-valued matrices. To that end, let \(\mathcal{H}^n\) denote the cone of Hermitian matrices of order \(n\), i.e.,
where superscript ’\(H\)’ denotes Hermitian (or complex) transposition. Then \(X\in \mathcal{H}_+^n\) if and only if
In other words,
Note that (6.27) implies skew-symmetry of \(\Im X\), i.e., \(\Im X = -\Im X^T\).
6.2.8 Nonnegative trigonometric polynomials¶
As a complex-valued variation of the sum-of-squares representation we consider trigonometric polynomials; optimization over cones of nonnegative trigonometric polynomials has several important engineering applications. Consider a trigonometric polynomial evaluated on the complex unit-circle
parametrized by \(x\in \R\times \mathbb{C}^n\). We are interested in characterizing the cone of trigonometric polynomials that are nonnegative on the angular interval \([0,\pi]\),
Consider a complex-valued basis function
The Riesz-Fejer Theorem states that a trigonometric polynomial \(f(z)\) in (6.29) is nonnegative (i.e., \(x \in K_{0,\pi}^n\)) if and only if for some \(q\in \mathbb{C}^{n+1}\)
Analogously to Sec. 6.2.6 (Nonnegative polynomials) we have a semidefinite characterization of the sum-of-squares representation, i.e., \(f(z)\geq 0,\ \forall z=e^{jt},\ t\in[0,2\pi]\) if and only if
where \(T_i^{n+1}\in \R^{(n+1)\times (n+1)}\) are Toeplitz matrices
When there is no ambiguity, we drop the superscript on \(T_i\). For example, for \(n=2\) we have
To prove correctness of the semidefinite characterization, we first note that
i.e.,
Next assume that (6.30) is satisfied. Then
with \(x_i = \langle qq^H, T_i \rangle\). Conversely, assume that (6.31) holds. Then
In other words, we have shown that
6.2.8.1 Nonnegativity on a subinterval¶
We next sketch a few useful extensions. An extension of the Riesz-Fejer Theorem states that a trigonometric polynomial \(f(z)\) of degree \(n\) is nonnegative on \(I(a,b)=\{ z \mid z=e^{jt}, \: t\in [a,b]\subseteq [0,\pi] \}\) if and only if it can be written as a weighted sum of squared trigonometric polynomials
where \(f_1, f_2, g\) are trigonemetric polynomials of degree \(n, n-d\) and \(d\), respectively, and \(g(z)\geq 0\) on \(I(a,b)\). For example \(g(z) = z + z^{-1} - 2\cos \alpha\) is nonnegative on \(I(0,\alpha)\), and it can be verified that \(f(z)\geq 0, \: \forall z\in I(0,\alpha)\) if and only if
for \(X_1\in \mathcal{H}_+^{n+1}\), \(X_2\in\mathcal{H}_+^n\), i.e.,
Similarly \(f(z)\geq 0, \: \forall z \in I(\alpha,\pi)\) if and only if
i.e.,
6.3 Semidefinite optimization case studies¶
6.3.1 Nearest correlation matrix¶
We consider the set
(shown in Fig. 6.1 for \(n=3\)). For \(A\in \mathcal{S}^n\) the nearest correlation matrix is
i.e., the projection of \(A\) onto the set \(S\). To pose this as a conic optimization we define the linear operator
which extracts and scales the lower-triangular part of \(U\). We then get a conic formulation of the nearest correlation problem exploiting symmetry of \(A-X\),
This is an example of a problem with both conic quadratic and semidefinite constraints in primal form. We can add different constraints to the problem, for example a bound \(\gamma\) on the smallest eigenvalue by replacing \(X\succeq 0\) with \(X\succeq \gamma I\).
6.3.2 Extremal ellipsoids¶
Given a polytope we can find the largest ellipsoid contained in the polytope, or the smallest ellipsoid containing the polytope (for certain representations of the polytope).
6.3.2.1 Maximal inscribed ellipsoid¶
Consider a polytope
The ellipsoid
is contained in \(S\) if and only if
or equivalently, if and only if
Since \(\mathbf{Vol}({\mathcal{E}})\approx \det(C)^{1/n}\) the maximum-volume inscribed ellipsoid is the solution to
In Sec. 6.2.2 (Eigenvalue optimization) we show how to maximize the determinant of a positive definite matrix.
6.3.2.2 Minimal enclosing ellipsoid¶
Next consider a polytope given as the convex hull of a set of points,
The ellipsoid
has \(\mathbf{Vol}({\mathcal{E'}})\approx \det(P)^{-1/n}\), so the minimum-volume enclosing ellipsoid is the solution to
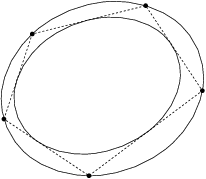
Fig. 6.2 Example of inner and outer ellipsoidal approximations of a pentagon in \(\real^2\).¶
6.3.3 Polynomial curve-fitting¶
Consider a univariate polynomial of degree \(n\),
Often we wish to fit such a polynomial to a given set of measurements or control points
i.e., we wish to determine coefficients \(x_i, \, i=0,\ldots,n\) such that
To that end, define the Vandermonde matrix
We can then express the desired curve-fit compactly as
i.e., as a linear expression in the coefficients \(x\). When the degree of the polynomial equals the number measurements, \(n=m\), the matrix \(A\) is square and non-singular (provided there are no duplicate rows), so we can can solve
to find a polynomial that passes through all the control points \((t_i, y_i)\). Similarly, if \(n>m\) there are infinitely many solutions satisfying the underdetermined system \(Ax=y\). A typical choice in that case is the least-norm solution
which (assuming again there are no duplicate rows) equals
On the other hand, if \(n<m\) we generally cannot find a solution to the overdetermined system \(Ax=y\), and we typically resort to a least-squares solution
which is given by the formula (see Sec. 8.5.1 (Linear regression and the normal equation))
In the following we discuss how the semidefinite characterizations of nonnegative polynomials (see Sec. 6.2.6 (Nonnegative polynomials)) lead to more advanced and useful polynomial curve-fitting constraints.
Nonnegativity. One possible constraint is nonnegativity on an interval,
\[f(t) := x_0 + x_1 t + \cdots + x_n t^n \geq 0, \, \forall t\in [a, b]\]with a semidefinite characterization embedded in \(x \in K^n_{a,b}\), see (6.25).
Monotonicity. We can ensure monotonicity of \(f(t)\) by requiring that \(f'(t)\geq 0\) (or \(f'(t)\leq 0\)), i.e.,
\[(x_1, 2 x_2, \ldots, n x_n) \in K^{n-1}_{a,b},\]or
\[-(x_1, 2 x_2, \ldots, n x_n) \in K^{n-1}_{a,b},\]respectively.
Convexity or concavity. Convexity (or concavity) of \(f(t)\) corresponds to \(f''(t)\geq 0\) (or \(f''(t)\leq 0\)), i.e.,
\[(2 x_2, 6 x_3, \ldots, (n-1)n x_n) \in K^{n-2}_{a,b},\]or
\[-(2 x_2, 6 x_3, \ldots, (n-1)n x_n) \in K^{n-2}_{a,b},\]respectively.
As an example, we consider fitting a smooth polynomial
to the points \(\{(-1,1),(0,0),(1,1)\}\), where smoothness is implied by bounding \(|f_n'(t)|\). More specifically, we wish to solve the problem
or equivalently
Finally, we use the characterizations \(K_{a,b}^n\) to get a conic problem
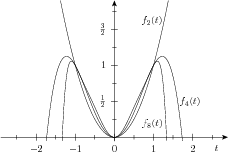
Fig. 6.3 Graph of univariate polynomials of degree 2, 4, and 8, respectively, passing through \(\{(-1,1),(0,0),(1,1)\}\). The higher-degree polynomials are increasingly smoother on \([-1,1]\).¶
In Fig. 6.3 we show the graphs for the resulting polynomails of degree 2, 4 and 8, respectively. The second degree polynomial is uniquely determined by the three constraints \(f_2(-1)=1\), \(f_2(0)=0\), \(f_2(1)=1\), i.e., \(f_2(t) = t^2\). Also, we obviously have a lower bound on the largest derivative \(\max_{t\in[-1,1]}|f_n'(t)|\geq 1\). The computed fourth degree polynomial is given by
after rounding coefficients to rational numbers. Furthermore, the largest derivative is given by
and \(f_4''(t)< 0\) on \((1/\sqrt{2},1]\) so, although not visibly clear, the polynomial is nonconvex on \([-1,1]\). In Fig. 6.4 we show the graphs of the corresponding polynomials where we added a convexity constraint \(f''_n(t)\geq 0\), i.e.,
In this case, we get
and the largest derivative increases to \(\frac{8}{5}\).
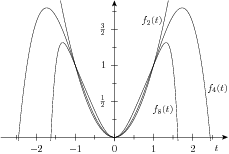
Fig. 6.4 Graph of univariate polynomials of degree \(2, 4,\) and \(8\), respectively, passing through \(\{(-1,1),(0,0),(1,1)\}\). The polynomials all have positive second derivative (i.e., they are convex) on \([-1,1]\) and the higher-degree polynomials are increasingly smoother on that interval.¶
6.3.4 Filter design problems¶
Filter design is an important application of optimization over trigonometric polynomials in signal processing. We consider a trigonometric polynomial
where \(a_k:=\Re (x_k)\), \(b_k:=\Im (x_k)\). If the function \(H(\omega)\) is nonnegative we call it a transfer function, and it describes how different harmonic components of a periodic discrete signal are attenuated when a filter with transfer function \(H(\omega)\) is applied to the signal.
We often wish a transfer function where \(H(\omega)\approx 1\) for \(0\leq \omega \leq \omega_p\) and \(H(\omega)\approx 0\) for \(\omega_s \leq \omega \leq \pi\) for given constants \(\omega_p, \omega_s\). One possible formulation for achieving this is
which corresponds to minimizing \(H(w)\) on the interval \([\omega_s,\pi]\) while allowing \(H(w)\) to depart from unity by a small amount \(\delta\) on the interval \([0, \omega_p]\). Using the results from Sec. 6.2.8 (Nonnegative trigonometric polynomials) (in particular (6.32), (6.33) and (6.34)), we can pose this as a conic optimization problem
which is a semidefinite optimization problem. In Fig. 6.5 we show \(H(\omega)\) obtained by solving (6.36) for \(n=10\), \(\delta=0.05\), \(\omega_p=\pi/4\) and \(\omega_s=\omega_p+\pi/8\).
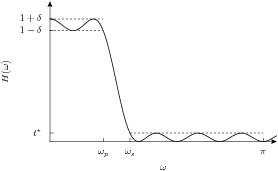
Fig. 6.5 Plot of lowpass filter transfer function.¶
6.3.5 Relaxations of binary optimization¶
Semidefinite optimization is also useful for computing bounds on difficult non-convex or combinatorial optimization problems. For example consider the binary linear optimization problem
In general, problem (6.37) is a very difficult non-convex problem where we have to explore \(2^n\) different objectives. Alternatively, we can use semidefinite optimization to get a lower bound on the optimal solution with polynomial complexity. We first note that
which is, in fact, equivalent to a rank constraint on a semidefinite variable,
By relaxing the rank 1 constraint on \(X\) we get a semidefinite relaxation of (6.37),
where we note that
Since (6.38) is a semidefinite optimization problem, it can be solved very efficiently. Suppose \(x^\star\) is an optimal solution for (6.37); then \((x^\star,x^\star (x^\star)^T)\) is also feasible for (6.38), but the feasible set for (6.38) is larger than the feasible set for (6.37), so in general the optimal solution of (6.38) serves as a lower bound. However, if the optimal solution \(X^\star\) of (6.38) has rank 1 we have found a solution to (6.37) also. The semidefinite relaxation can also be used in a branch-bound mixed-integer exact algorithm for (6.37).
We can tighten (or improve) the relaxation (6.38) by adding other constraints that cut away parts of the feasible set, without excluding rank 1 solutions. By tightening the relaxation, we reduce the gap between the optimal values of the original problem and the relaxation. For example, we can add the constraints
and so on. This will usually have a dramatic impact on solution times and memory requirements. Already constraining a semidefinite matrix to be doubly nonnegative (\(X_{ij}\geq 0\)) introduces additional \(n^2\) linear inequality constraints.
6.3.6 Relaxations of boolean optimization¶
Similarly to Sec. 6.3.5 (Relaxations of binary optimization) we can use semidefinite relaxations of boolean constraints \(x\in \{-1,+1\}^n\). To that end, we note that
with a semidefinite relaxation \(X \succeq xx^T\) of the rank-1 constraint.
As a (standard) example of a combinatorial problem with boolean constraints, we consider an undirected graph \(G=(V,E)\) described by a set of vertices \(V=\{v_1, \dots, v_n \}\) and a set of edges \(E=\{ (v_i,v_j) \mid v_i,v_j\in V, \: i\neq j\}\), and we wish to find the cut of maximum capacity. A cut \(C\) partitions the nodes \(V\) into two disjoint sets \(S\) and \(T=V\setminus S\), and the cut-set \(I\) is the set of edges with one node in \(S\) and another in \(T\), i.e.,
The capacity of a cut is then defined as the number of edges in the cut-set, \(|I|\).
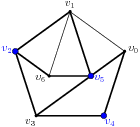
Fig. 6.6 Undirected graph. The cut \(\{ v_2, v_4, v_5 \}\) has capacity 9 (thick edges).¶
To maximize the capacity of a cut we define the symmetric adjacency matrix \(A\in\mathcal{S}^n\),
where \(n=|V|\), and let
Suppose \(v_i\in S\). Then \(1-x_i x_j=0\) if \(v_j\in S\) and \(1-x_i x_j = 2\) if \(v_j\notin S\), so we get an expression for the capacity as
and discarding the constant term \(e^T A e\) gives us the MAX-CUT problem
with a semidefinite relaxation
