2 Linear optimization¶
In this chapter we discuss various aspects of linear optimization. We first introduce the basic concepts of linear optimization and discuss the underlying geometric interpretations. We then give examples of the most frequently used reformulations or modeling tricks used in linear optimization, and finally we discuss duality and infeasibility theory in some detail.
2.1 Introduction¶
2.1.1 Basic notions¶
The most basic type of optimization is linear optimization. In linear optimization we minimize a linear function given a set of linear constraints. For example, we may wish to minimize a linear function
under the constraints that
The function we minimize is often called the objective function; in this case we have a linear objective function. The constraints are also linear and consist of both linear equalities and inequalities. We typically use more compact notation
and we call (2.1) a linear optimization problem. The domain where all constraints are satisfied is called the feasible set; the feasible set for (2.1) is shown in Fig. 2.1.
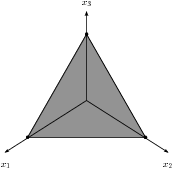
Fig. 2.1 Feasible set for \(x_1+x_2+x_3=1\) and \(x_1,x_2,x_3\geq 0.\)¶
For this simple problem we see by inspection that the optimal value of the problem is \(-1\) obtained by the optimal solution
Linear optimization problems are typically formulated using matrix notation. The standard form of a linear minimization problem is:
For example, we can pose (2.1) in this form with
There are many other formulations for linear optimization problems; we can have different types of constraints,
and different bounds on the variables
or we may have no bounds on some \(x_i\), in which case we say that \(x_i\) is a free variable. All these formulations are equivalent in the sense that by simple linear transformations and introduction of auxiliary variables they represent the same set of problems. The important feature is that the objective function and the constraints are all linear in \(x\).
2.1.2 Geometry of linear optimization¶
A hyperplane is a subset of \(\real^n\) defined as \(\{ x \mid a^T(x - x_0) = 0\}\) or equivalently \(\{ x \mid a^T x = \gamma \}\) with \(a^Tx_0 = \gamma\), see Fig. 2.2.
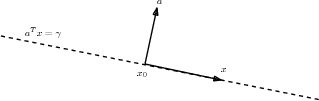
Fig. 2.2 The dashed line illustrates a hyperplane \(\{x\mid a^Tx=\gamma\}\).¶
Thus a linear constraint
with \(A \in \R^{m\times n}\) represents an intersection of \(m\) hyperplanes.
Next, consider a point \(x\) above the hyperplane in Fig. 2.3. Since \(x-x_0\) forms an acute angle with \(a\) we have that \(a^T(x-x_0)\geq 0\), or \(a^Tx \geq \gamma\). The set \(\{ x \mid a^T x \geq \gamma \}\) is called a halfspace. Similarly the set \(\{ x \mid a^T x \leq \gamma \}\) forms another halfspace; in Fig. 2.3 it corresponds to the area below the dashed line.
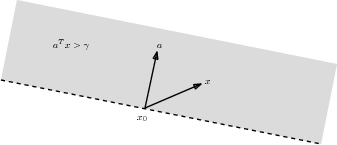
Fig. 2.3 The grey area is the halfspace \(\{x\mid a^T x\geq \gamma\}\).¶
A set of linear inequalities
corresponds to an intersection of halfspaces and forms a polyhedron, see Fig. 2.4.

Fig. 2.4 A polyhedron formed as an intersection of halfspaces.¶
The polyhedral description of the feasible set gives us a very intuitive interpretation of linear optimization, which is illustrated in Fig. 2.5. The dashed lines are normal to the objective \(c=(-1,1)\), and to minimize \(c^T x\) we move as far as possible in the opposite direction of \(c\), to the furthest position where a dashed line intersect the polyhedron; an optimal solution is therefore always either a vertex of the polyhedron, or an entire facet of the polyhedron may be optimal.
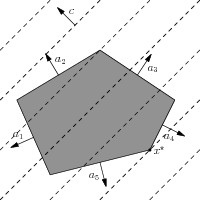
Fig. 2.5 Geometric interpretation of linear optimization. The optimal solution \(x^\star\) is at a point where the normals to \(c\) (the dashed lines) intersect the polyhedron.¶
The polyhedron shown in the figure is nonempty and bounded, but this is not always the case for polyhedra arising from linear inequalities in optimization problems. In such cases the optimization problem may be infeasible or unbounded, which we will discuss in detail in Sec. 2.3 (Infeasibility in linear optimization).
2.2 Linear modeling¶
In this section we present useful reformulation techniques and standard tricks which allow constructing more complicated models using linear optimization. It is also a guide through the types of constraints which can be expressed using linear (in)equalities.
2.2.1 Maximum¶
The inequality \(t\geq\max\{x_1,\ldots,x_n\}\) is equivalent to a simultaneous sequence of \(n\) inequalities
and similarly \(t\leq\min\{x_1,\ldots,x_n\}\) is the same as
Of course the same reformulation applies if each \(x_i\) is not a single variable but a linear expression. In particular, we can consider convex piecewise-linear functions \(f:\R^n \mapsto \R\) defined as the maximum of affine functions (see Fig. 2.6):
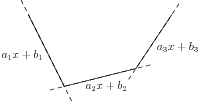
Fig. 2.6 A convex piecewise-linear function (solid lines) of a single variable \(x\). The function is defined as the maximum of 3 affine functions.¶
The epigraph \(f(x) \leq t\) (see Sec. 12 (Notation and definitions)) has an equivalent formulation with \(m\) inequalities:
Piecewise-linear functions have many uses linear in optimization; either we have a convex piecewise-linear formulation from the onset, or we may approximate a more complicated (nonlinear) problem using piecewise-linear approximations, although with modern nonlinear optimization software it is becoming both easier and more efficient to directly formulate and solve nonlinear problems without piecewise-linear approximations.
2.2.2 Absolute value¶
The absolute value of a scalar variable, \(| x | := \max \{ x, -x \}\), is a special case of Sec. 2.2.1 (Maximum). To model the epigraph
we can thus use two inequalities
2.2.3 The \(\ell_1\) norm¶
All norms are convex functions, but the \(\ell_1\) and \(\ell_\infty\) norms are of particular interest for linear optimization. The \(\ell_1\) norm of vector \(x\in\R^n\) is defined as
To model the epigraph
we introduce the following system
with additional (auxiliary) variable \(z\in\R^n\). Clearly (2.3) and (2.4) are equivalent, in the sense that they have the same projection onto the space of \(x\) and \(t\) variables. Therefore, we can model (2.3) using linear (in)equalities
with auxiliary variables \(z\). Similarly, we can describe the epigraph of the norm of an affine function of \(x\),
as
where \(a_i\) is the \(i-\)th row of \(A\) (taken as a column-vector).
The \(\ell_1\) norm is overwhelmingly popular as a convex approximation of the cardinality (i.e., number on nonzero elements) of a vector \(x\). For example, suppose we are given an underdetermined linear system
where \(A\in \R^{m\times n}\) and \(m\ll n\). The basis pursuit problem
uses the \(\ell_1\) norm of \(x\) as a heuristic for finding a sparse solution (one with many zero elements) to \(Ax=b\), i.e., it aims to represent \(b\) as a linear combination of few columns of \(A\). Using (2.5) we can pose the problem as a linear optimization problem,
where \(e=(1,\dots,1)^T\).
2.2.4 The \(\ell_\infty\) norm¶
The \(\ell_\infty\) norm of a vector \(x\in\R^n\) is defined as
which is another example of a simple piecewise-linear function. Using Sec. 2.2.2 (Absolute value) we model
as
Again, we can also consider affine functions of \(x\), i.e.,
which can be described as
It is interesting to note that the \(\ell_1\) and \(\ell_\infty\) norms are dual. For any norm \(\| \cdot \|\) on \(\R^n\), the dual norm \(\| \cdot \|_*\) is defined as
Let us verify that the dual of the \(\ell_\infty\) norm is the \(\ell_1\) norm. Consider
Obviously the maximum is attained for
i.e., \(\| x \|_{*,\infty} = \sum_i | x_i | = \| x \|_1\). Similarly, consider the dual of the \(\ell_1\) norm,
To maximize \(x^T v\) subject to \(|v_1|+\cdots+|v_n|\leq 1\) we simply pick the element of \(x\) with largest absolute value, say \(|x_k|\), and set \(v_k=\pm 1\), so that \(\|x\|_{*,1} = |x_k| = \|x\|_\infty\). This illustrates a more general property of dual norms, namely that \(\|x\|_{**}=\|x\|\).
2.2.5 Homogenization¶
Consider the linear-fractional problem
Perhaps surprisingly, it can be turned into a linear problem if we homogenize the linear constraint, i.e. replace it with \(Fy=gz\) for a single variable \(z\in\real\). The full new optimization problem is
If \(x\) is a feasible point in (2.8) then \(z=(c^Tx+d)^{-1},\ y=xz\) is feasible for (2.9) with the same objective value. Conversely, if \((y,z)\) is feasible for (2.9) then \(x=y/z\) is feasible in (2.8) and has the same objective value, at least when \(z\neq 0\). If \(z=0\) and \(x\) is any feasible point for (2.8) then \(x+ty, t\to +\infty\) is a sequence of solutions of (2.8) converging to the value of (2.9). We leave it for the reader to check those statements. In either case we showed an equivalence between the two problems.
Note that, as the sketch of proof above suggests, the optimal value in (2.8) may not be attained, even though the one in the linear problem (2.9) always is. For example, consider a pair of problems constructed as above:
Both have an optimal value of \(-1\), but on the left we can only approach it arbitrarily closely.
2.2.6 Sum of largest and smallest elements¶
Suppose \(x\in\real^n\) and that \(m\) is a positive integer. Consider the problem
with new variables \(t\in\real\), \(u_i\in\real^n\). It is easy to see that fixing a value for \(t\) determines the rest of the solution. For the sake of simplifying notation let us assume for a moment that \(x\) is sorted:
If \(t\in[x_k,x_{k+1})\) then \(u_l=0\) for \(l\geq k+1\) and \(u_l=x_l-t\) for \(l\leq k\) in the optimal solution. Therefore, the objective value under the assumption \(t\in[x_k,x_{k+1})\) is
which is a linear function minimized at one of the endpoints of \([x_k,x_{k+1})\). Now we can compute
It follows that \(\mathrm{obj}_{x_k}\) has a minimum for \(k=m\), and therefore the optimum value of (2.10) is simply
Since the assumption that \(x\) is sorted was only a notational convenience, we conclude that in general the optimization model (2.10) computes the sum of \(m\) largest entries in \(x\). In Sec. 2.4 (Duality in linear optimization) we will show a conceptual way of deriving this model.
By a similar argument, or replacing \(x\) with \(-x\), we can we also derive a model computing the sum of \(m\) smallest entries in \(x_1,\ldots,x_n\) as follows:
2.2.7 Drawdown¶
We say a sequence \(x_1,\ldots,x_n\) has drawdown bounded by \(d\) if
Therefore a sequence with bounded drawdown is allowed to increase arbitrarily but is not allowed to drop down by more than \(d\) from the last achieved maximum. Drawdown constraints appear in some portfolio optimization models. We can formulate a linear model of (2.12) by successively computing the cumulative maxima of \(x\) (see Sec. 2.2.1 (Maximum)):
2.3 Infeasibility in linear optimization¶
In this section we discuss the basic theory of primal infeasibility certificates for linear problems. These ideas will be developed further after we have introduced duality in the next section.
One of the first issues one faces when presented with an optimization problem is whether it has any solutions at all. As we discussed previously, for a linear optimization problem
the feasible set
is a convex polytope. We say the problem is feasible if \({\cal F}_p\neq\emptyset\) and infeasible otherwise.
Consider the optimization problem:
This problem is infeasible. We see it by taking a linear combination of the constraints with coefficients \(y=(1,2,-1)^T\):
This clearly proves infeasibility: the left-hand side is negative and the right-hand side is positive, which is impossible.
2.3.1 Farkas’ lemma¶
In the last example we proved infeasibility of the linear system by exhibiting an explicit linear combination of the equations, such that the right-hand side (constant) is positive while on the left-hand side all coefficients are negative or zero. In matrix notation, such a linear combination is given by a vector \(y\) such that \(A^Ty\leq 0\) and \(b^Ty>0\). The next lemma shows that infeasibility of (2.14) is equivalent to the existence of such a vector.
Given \(A\) and \(b\) as in (2.14), exactly one of the two statements is true:
There exists \(x\geq 0\) such that \(Ax = b\).
There exists \(y\) such that \(A^T y \leq 0\) and \(b^T y > 0\).
Let \(a_1,\ldots,a_n\) be the columns of \(A\). The set \(\{Ax \mid x\geq 0\}\) is a closed convex cone spanned by \(a_1,\ldots,a_n\). If this cone contains \(b\) then we have the first alternative. Otherwise the cone can be separated from the point \(b\) by a hyperplane passing through \(0\), i.e. there exists \(y\) such that \(y^Tb>0\) and \(y^Ta_i\leq 0\) for all \(i\). This is equivalent to the second alternative. Finally, 1. and 2. are mutually exclusive, since otherwise we would have
Farkas’ lemma implies that either the problem (2.14) is feasible or there is a certificate of infeasibility \(y\). In other words, every time we classify model as infeasible, we can certify this fact by providing an appropriate \(y\), as in Example 2.3.
2.3.2 Locating infeasibility¶
As we already discussed, the infeasibility certificate \(y\) gives coefficients of a linear combination of the constraints which is infeasible “in an obvious way”, that is positive on one side and negative on the other. In some cases, \(y\) may be very sparse, i.e. it may have very few nonzeros, which means that already a very small subset of the constraints is the root cause of infeasibility. This may be interesting if, for example, we are debugging a large model which we expected to be feasible and infeasibility is caused by an error in the problem formulation. Then we only have to consider the sub-problem formed by constraints with index set \(\{j\mid y_j\neq 0\}\).
As a cautionary note consider the constraints
Any problem with those constraints is infeasible, but dropping any one of the inequalities creates a feasible subproblem.
2.4 Duality in linear optimization¶
Duality is a rich and powerful theory, central to understanding infeasibility and sensitivity issues in linear optimization. In this section we only discuss duality in linear optimization at a descriptive level suited for practitioners; we refer to Sec. 8 (Duality in conic optimization) for a more in-depth discussion of duality for general conic problems.
2.4.1 The dual problem¶
Primal problem
We consider as always a linear optimization problem in standard form:
We denote the optimal objective value in (2.15) by \(p^\star\). There are three possibilities:
The problem is infeasible. By convention \(p^\star=+\infty\).
\(p^\star\) is finite, in which case the problem has an optimal solution.
\(p^\star=-\infty\), meaning that there are feasible solutions with \(c^Tx\) decreasing to \(-\infty\), in which case we say the problem is unbounded.
Lagrange function
We associate with (2.15) a so-called Lagrangian function \(L:\R^n\times \R^m \times \R_+^n \to \R\) that augments the objective with a weighted combination of all the constraints,
The variables \(y\in \R^m\) and \(s\in \R_+^n\) are called Lagrange multipliers or dual variables. For any feasible \(x^*\in{\cal F}_p\) and any \((y^*,s^*)\in\real^m\times\real_+^n\) we have
Note the we used the nonnegativity of \(s^*\), or in general of any Lagrange multiplier associated with an inequality constraint. The dual function is defined as the minimum of \(L(x,y,s)\) over \(x\). Thus the dual function of (2.15) is
Dual problem
For every \((y,s)\) the value of \(g(y,s)\) is a lower bound for \(p^\star\). To get the best such bound we maximize \(g(y,s)\) over all \((y,s)\) and get the dual problem:
The optimal value of (2.16) will be denoted \(d^\star\). As in the case of (2.15) (which from now on we call the primal problem), the dual problem can be infeasible (\(d^\star=-\infty\)), have an optimal solution (\(-\infty<d^\star<+\infty\)) or be unbounded (\(d^\star=+\infty\)). Note that the roles of \(-\infty\) and \(+\infty\) are now reversed because the dual is a maximization problem.
As an example, let us derive the dual of the basis pursuit formulation (2.7). It would be possible to add auxiliary variables and constraints to force that problem into the standard form (2.15) and then just apply the dual transformation as a black box, but it is both easier and more instructive to directly write the Lagrangian:
where \(e=(1,\ldots,1)^T\), with Lagrange multipliers \(y\in \R^m\) and \(u,v\in \R^n_+\). The dual function
is only bounded below if \(e = u + v\) and \(A^Ty = u-v\), hence the dual problem is
It is not hard to observe that an equivalent formulation of (2.17) is simply
which should be associated with duality between norms discussed in Example 2.2.
We can similarly derive the dual of problem (2.16). If we write it simply as
then the Lagrangian is
with \(u\in\real_+^n\), so that now \(L(y,u)\geq b^Ty\) for any feasible \(y\). Calculating \(\min_u\max_y L(y,u)\) is now equivalent to the problem
so, as expected, the dual of the dual recovers the original primal problem.
2.4.2 Weak and strong duality¶
Suppose \(x^*\) and \((y^*, s^*)\) are feasible points for the primal and dual problems (2.15) and (2.16), respectively. Then we have
so the dual objective value is a lower bound on the objective value of the primal. In particular, any dual feasible point \((y^*, s^*)\) gives a lower bound:
and we immediately get the next lemma.
\(d^\star\leq p^\star\).
It follows that if \(b^Ty^* = c^Tx^*\) then \(x^*\) is optimal for the primal, \((y^*,s^*)\) is optimal for the dual and \(b^Ty^* = c^Tx^*\) is the common optimal objective value. This way we can use the optimal dual solution to certify optimality of the primal solution and vice versa.
The remarkable property of linear optimization is that \(d^\star=p^\star\) holds in the most interesting scenario when the primal problem is feasible and bounded. It means that the certificate of optimality mentioned in the previous paragraph always exists.
If at least one of \(d^\star,p^\star\) is finite then \(d^\star=p^\star\).
Suppose \(-\infty<p^\star<\infty\); the proof in the dual case is analogous. For any \(\varepsilon>0\) consider the feasibility problem with variable \(x\geq 0\) and constraints
Optimality of \(p^\star\) implies that the above problem is infeasible. By Lemma 2.1 there exists \(\hat{y}=[y_0\ y]^T\) such that
If \(y_0=0\) then \(A^Ty\leq 0\) and \(b^Ty>0\), which by Lemma 2.1 again would mean that the original primal problem was infeasible, which is not the case. Hence we can rescale so that \(y_0=1\) and then we get
The first inequality above implies that \(y\) is feasible for the dual problem. By letting \(\varepsilon\to 0\) we obtain \(d^\star\geq p^\star\).
We can exploit strong duality to freely choose between solving the primal or dual version of any linear problem.
Suppose that \(x\) is now a constant vector. Consider the following problem with variable \(z\):
The maximum is attained when \(z\) indicates the positions of \(m\) largest entries in \(x\), and the objective value is then their sum. This formulation, however, cannot be used when \(x\) is another variable, since then the objective function is no longer linear. Let us derive the dual problem. The Lagrangian is
with \(u,s\geq 0\). Since \(s_i\geq0\) is arbitrary and not otherwise constrained, the equality \(x_i-t+s_i-u_i=0\) is the same as \(u_i+t\geq x_i\) and for the dual problem we get
which is exactly the problem (2.10) we studied in Sec. 2.2.6 (Sum of largest and smallest elements). Strong duality now implies that (2.10) computes the sum of \(m\) biggest entries in \(x\).
2.4.3 Duality and infeasibility: summary¶
We can now expand the discussion of infeasibility certificates in the context of duality. Farkas’ lemma Lemma 2.1 can be dualized and the two versions can be summarized as follows:
Weak and strong duality for linear optimization now lead to the following conclusions:
If the problem is primal feasible and has finite objective value (\(-\infty<p^\star<\infty\)) then so is the dual and \(d^\star=p^\star\). We sometimes refer to this case as primal and dual feasible. The dual solution certifies the optimality of the primal solution and vice versa.
If the primal problem is feasible but unbounded (\(p^\star=-\infty\)) then the dual is infeasible (\(d^\star=-\infty\)). Part (ii) of Farkas’ lemma provides a certificate of this fact, that is a vector \(x\) with \(x\geq0\), \(Ax=0\) and \(c^Tx<0\). In fact it is easy to give this statement a geometric interpretation. If \(x^0\) is any primal feasible point then the infinite ray
\[t\to x_0+tx,\ t\in[0,\infty)\]belongs to the feasible set \({\cal F}_p\) because \(A(x_0+tx)=b\) and \(x_0+tx\geq0\). Along this ray the objective value is unbounded below:
\[c^T(x_0+tx)=c^Tx_0+t(c^Tx) \to -\infty.\]If the primal problem is infeasible (\(p^\star=\infty\)) then a certificate of this fact is provided by part (i). The dual problem may be unbounded (\(d^\star=\infty\)) or infeasible (\(d^\star=-\infty\)).
Weak and strong duality imply that the only case when \(d^\star\neq p^\star\) is when both primal and dual problem are infeasible (\(d^\star=-\infty\), \(p^\star=\infty\)), for example:
2.4.4 Dual values as shadow prices¶
Dual values are related to shadow prices, as they measure, under some nondegeneracy assumption, the sensitivity of the objective value to a change in the constraint. Consider again the primal and dual problem pair (2.15) and (2.16) with feasible sets \({\cal F}_p\) and \({\cal F}_d\) and with a primal-dual optimal solution \((x^*,y^*,s^*)\).
Suppose we change one of the values in \(b\) from \(b_i\) to \(b_i'\). This corresponds to moving one of the hyperplanes defining \({\cal F}_p\), and in consequence the optimal solution (and the objective value) may change. On the other hand, the dual feasible set \({\cal F}_d\) is not affected. Assuming that the solution \((y^*,s^*)\) was a unique vertex of \({\cal F}_d\) this point remains optimal for the dual after a sufficiently small change of \(b\). But then the change of the dual objective is
and by strong duality the primal objective changes by the same amount.
An optimization student wants to save money on the diet while remaining healthy. A healthy diet requires at least \(P=6\) units of protein, \(C=15\) units of carbohydrates, \(F=5\) units of fats and \(V=7\) units of vitamins. The student can choose from the following products:
P |
C |
F |
V |
price |
|
takeaway |
3 |
3 |
2 |
1 |
5 |
vegetables |
1 |
2 |
0 |
4 |
1 |
bread |
0.5 |
4 |
1 |
0 |
2 |
The problem of minimizing cost while meeting dietary requirements is
If \(y_1,y_2,y_3,y_4\) are the dual variables associated with the four inequality constraints then the (unique) primal-dual optimal solution to this problem is approximately:
with optimal cost \(p^\star=12.5\). Note \(y_2=0\) indicates that the second constraint is not binding. Indeed, we could increase \(C\) to \(18\) without affecting the optimal solution. The remaining constraints are binding.
Improving the intake of protein by \(1\) unit (increasing \(P\) to \(7\)) will increase the cost by \(0.42\), while doing the same for fat will cost an extra \(1.78\) per unit. If the student had extra money to improve one of the parameters then the best choice would be to increase the intake of vitamins, with shadow price of just \(0.14\).
If one month the student only had \(12\) units of money and was willing to relax one of the requirements then the best choice is to save on fats: the necessary reduction of \(F\) is smallest, namely \(0.5\cdot 1.78^{-1}=0.28\). Indeed, with the new value of \(F=4.72\) the same problem solves to \(p^\star= 12\) and \(x=(1.08,1.48,2.56)\).
We stress that a truly balanced diet problem should also include upper bounds.
