10 Quadratic optimization¶
In this chapter we discuss convex quadratic and quadratically constrained optimization. Our discussion is fairly brief compared to the previous chapters for three reasons; (i) convex quadratic optimization is a special case of conic quadratic optimization, (ii) for most convex problems it is actually more computationally efficient to pose the problem in conic form, and (iii) duality theory (including infeasibility certificates) is much simpler for conic quadratic optimization. Therefore, we generally recommend a conic quadratic formulation, see Sec. 3 (Conic quadratic optimization) and especially Sec. 3.2.3 (Convex quadratic sets).
10.1 Quadratic objective¶
A standard (convex) quadratic optimization problem
with \(Q\in\PSD^n\) is conceptually a simple extension of a standard linear optimization problem with a quadratic term \(x^T Q x\). Note the important requirement that \(Q\) is symmetric positive semidefinite; otherwise the objective function would not be convex.
10.1.1 Geometry of quadratic optimization¶
Quadratic optimization has a simple geometric interpretation; we minimize a convex quadratic function over a polyhedron., see Fig. 10.1. It is intuitively clear that the following different cases can occur:
The optimal solution \(x^\star\) is at the boundary of the polyhedron (as shown in Fig. 10.1). At \(x^\star\) one of the hyperplanes is tangential to an ellipsoidal level curve.
The optimal solution is inside the polyhedron; this occurs if the unconstrained minimizer \(\arg\min_x \half x^T Q x + c^T x=-Q^\dagger c\) (i.e., the center of the ellipsoidal level curves) is inside the polyhedron. From now on \(Q^\dagger\) denotes the pseudoinverse of \(Q\); in particular \(Q^\dagger=Q^{-1}\) if \(Q\) is positive definite.
If the polyhedron is unbounded in the opposite direction of \(c\), and if the ellipsoid level curves are degenerate in that direction (i.e., \(Qc=0\)), then the problem is unbounded. If \(Q\in \mathcal{S}_{++}^n\), then the problem cannot be unbounded.
The problem is infeasible, i.e., \(\{ x \mid Ax=b, \: x\geq 0 \}=\emptyset\).
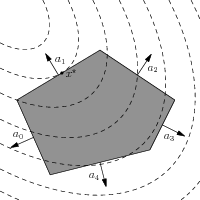
Fig. 10.1 Geometric interpretation of quadratic optimization. At the optimal point \(x^\star\) the hyperplane \(\{x\mid a_1^T x=b\}\) is tangential to an ellipsoidal level curve.¶
Possibly because of its simple geometric interpretation and similarity to linear optimization, quadratic optimization has been more widely adopted by optimization practitioners than conic quadratic optimization.
10.1.2 Duality in quadratic optimization¶
The Lagrangian function (Sec. 8.3 (Lagrangian and the dual problem)) for (10.1) is
with Lagrange multipliers \(s\in \R^n_+\), and from \(\nabla_x L(x,y,s)=0\) we get the necessary first-order optimality condition
i.e. \((A^Ty+s-c)\in \mathcal{R}(Q)\). Then
which can be substituted into (10.2) to give a dual function
Thus we get a dual problem
or alternatively, using the optimality condition \(Qx = A^T y + s - c\) we can write
Note that this is an unusual dual problem in the sense that it involves both primal and dual variables.
Weak duality, strong duality under Slater constraint qualification and Farkas infeasibility certificates work similarly as in Sec. 8 (Duality in conic optimization). In particular, note that the constraints in both (10.1) and (10.4) are linear, so Lemma 2.4 applies and we have:
10.1.3 Conic reformulation¶
Suppose we have a factorization \(Q=F^TF\) where \(F\in\real^{k\times n}\), which is most interesting when \(k \ll n\). Then \(x^TQx=x^TF^TFx=\|Fx\|_2^2\) and the conic quadratic reformulation of (10.1) is
with dual problem
Note that in an optimal primal-dual solution we have \(r=\frac12\|Fx\|_2^2\), hence the complementary slackness for \(\Qr^{k+2}\) demands \(v=-Fx\) and \(-F^TFv=Qx\), as well as \(u=\frac12 \|v\|_2^2=\frac12 x^TQx\). This justifies why some of the dual variables in (10.6) and (10.4) have the same names - they are in fact equal, and so both the primal and dual solution to the original quadratic problem can be recovered from the primal-dual solution to the conic reformulation.
10.2 Quadratically constrained optimization¶
A general convex quadratically constrained quadratic optimization problem is
where \(Q_i\in \mathcal{S}_+^n\). This corresponds to minimizing a convex quadratic function over an intersection of convex quadratic sets such as ellipsoids or affine halfspaces. Note the important requirement \(Q_i\succeq 0\) for all \(i=0,\ldots,m\), so that the objective function is convex and the constraints characterize convex sets. For example, neither of the constraints
characterize convex sets, and therefore cannot be included.
10.2.1 Duality in quadratically constrained optimization¶
The Lagrangian function for (10.7) is
where
From the Lagrangian we get the first-order optimality conditions
and similar to the case of quadratic optimization we get a dual problem
or equivalently
Using a general version of the Schur Lemma for singular matrices, we can also write (10.9) as an equivalent semidefinite optimization problem,
Feasibility in quadratically constrained optimization is characterized by the following conditions (assuming Slater constraint qualification or other conditions to exclude ill-posed problems):
Either the primal problem (10.7) is feasible or there exists \(\lambda \geq 0, \: \lambda \neq 0\) satisfying
(10.12)¶\[\begin{split}\sum_{i=1}^m \lambda_i \left[ \begin{array}{cc} 2r_i & c_i^T \\ c_i & Q_i \end{array} \right] \succ 0.\end{split}\]Either the dual problem (10.10) is feasible or there exists \(x\in \R^n\) satisfying
(10.13)¶\[Q_0 x = 0, \qquad c_0^T x < 0, \qquad Q_ix = 0, \qquad c_i^T x = 0, \quad i=1,\dots, m.\]
To see why the certificate proves infeasibility, suppose for instance that (10.12) and (10.7) are simultaneously satisfied. Then
and we have a contradiction, so (10.12) certifies infeasibility.
10.2.2 Conic reformulation¶
If \(Q_i=F_i^TF_i\) for \(i=0,\ldots,m\), where \(F_i\in\real^{k_i\times n}\) then we get a conic quadratic reformulation of (10.7):
The primal and dual solution of (10.14) recovers the primal and dual solution of (10.7) similarly as for quadratic optimization in Sec. 10.1.3 (Conic reformulation). Let us see for example, how a (conic) primal infeasibility certificate for (10.14) implies an infeasibility certificate in the form (10.12). Infeasibility in (10.14) involves only the last set of conic constraints. We can derive the infeasibility certificate for those constraints from Lemma 8.3 or by directly writing the Lagrangian
The dual maximization problem is unbounded (i.e. the primal problem is infeasible) if we have
We claim that \(\lambda=v\) is an infeasibility certificate in the sense of (10.12). We can assume \(v_i>0\) for all \(i\), as otherwise \(w_i=0\) and we can take \(u_i=0\) and skip the \(i\)-th coordinate. Let \(M\) denote the matrix appearing in (10.12) with \(\lambda=v\). We show that \(M\) is positive definite:
10.3 Example: Factor model¶
Recall from Sec. 3.3.3 (Markowitz portfolio optimization) that the standard Markowitz portfolio optimization problem is
where \(\mu\in \R^n\) is a vector of expected returns for \(n\) different assets and \(\Sigma \in \mathcal{S}_+^n\) denotes the corresponding covariance matrix. Problem (10.15) maximizes the expected return of an investment given a budget constraint and an upper bound \(\gamma\) on the allowed risk. Alternatively, we can minimize the risk given a lower bound \(\delta\) on the expected return of investment, i.e., we can solve the problem
Both problems (10.15) and (10.16) are equivalent in the sense that they describe the same Pareto-optimal trade-off curve by varying \(\delta\) and \(\gamma\).
Next consider a factorization
for some \(V\in\R^{k\times n}\). We can then rewrite both problems (10.15) and (10.16) in conic quadratic form as
and
respectively. Given \(\Sigma\succ 0\), we may always compute a factorization (10.17) where \(V\) is upper-triangular (Cholesky factor). In this case \(k=n\), i.e., \(V\in\R^{n\times n}\), so there is little difference in complexity between the conic and quadratic formulations. However, in practice, better choices of \(V\) are either known or readily available. We mention two examples.
Data matrix
\(\Sigma\) might be specified directly in the form (10.17), where \(V\) is a normalized data-matrix with \(k\) observations of market data (for example daily returns) of the \(n\) assets. When the observation horizon \(k\) is shorter than \(n\), which is typically the case, the conic representation is both more parsimonious and has better numerical properties.
Factor model
For a factor model we have
where \(D=\Diag(w)\) is a diagonal matrix, \(U \in \R^{k\times n}\) represents the exposure of assets to risk factors and \(R\in \real^{k\times k}\) is the covariance matrix of factors. Importantly, we normally have a small number of factors (\(k\ll n\)), so it is computationally much cheaper to find a Cholesky decomposition \(R=F^TF\) with \(F\in\real^{k\times k}\). This combined gives us \(\Sigma=V^TV\) for
of dimensions \((n+k)\times n\). The dimensions of \(V\) are larger than the dimensions of the Cholesky factors of \(\Sigma\), but \(V\) is very sparse, which usually results in a significant reduction of solution time. The resulting risk minimization conic problem can ultimately be written as:
