5 Exponential cone optimization¶
So far we discussed optimization problems involving the major “polynomial” families of cones: linear, quadratic and power cones. In this chapter we introduce a single new object, namely the three-dimensional exponential cone, together with examples and applications. The exponential cone can be used to model a variety of constraints involving exponentials and logarithms.
5.1 Exponential cone¶
The exponential cone is a convex subset of \(\R^3\) defined as
Thus the exponential cone is the closure in \(\R^3\) of the set of points which satisfy
When working with logarithms, a convenient reformulation of (5.2) is
Alternatively, one can write the same condition as
which immediately shows that \(\EXP\) is in fact a cone, i.e. \(\alpha x\in \EXP\) for \(x\in \EXP\) and \(\alpha\geq 0\). Convexity of \(\EXP\) follows from the fact that the Hessian of \(f(x,y)=y\exp(x/y)\), namely
is positive semidefinite for \(y>0\).
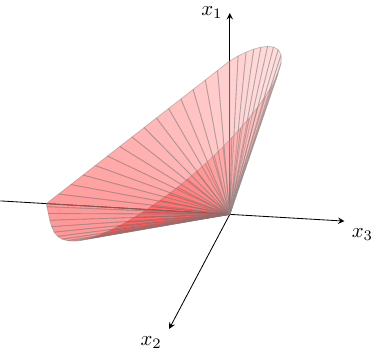
Fig. 5.1 The boundary of the exponential cone \(\EXP\).¶
5.2 Modeling with the exponential cone¶
Extending the conic optimization toolbox with the exponential cone leads to new types of constraint building blocks and new types of representable sets. In this section we list the basic operations available using the exponential cone.
5.2.1 Exponential¶
The epigraph \(t\geq e^x\) is a section of \(\EXP\):
5.2.2 Logarithm¶
Similarly, we can express the hypograph \(t\leq \log{x},\ x\geq 0\):
5.2.3 Entropy¶
The entropy function \(H(x) = -x\log{x}\) can be maximized using the following representation which follows directly from (5.3):
5.2.4 Relative entropy¶
The relative entropy or Kullback-Leiber divergence of two probability distributions is defined in terms of the function \(D(x,y)=x\log(x/y)\). It is convex, and the minimization problem \(t\geq D(x,y)\) is equivalent to
Because of this reparametrization the exponential cone is also referred to as the relative entropy cone, leading to a class of problems known as REPs (relative entropy problems). Having the relative entropy function available makes it possible to express epigraphs of other functions appearing in REPs, for instance:
5.2.5 Softplus function¶
In neural networks the function \(f(x)=\log(1+e^x)\), known as the softplus function, is used as an analytic approximation to the rectifier activation function \(r(x)=x^+=\max(0,x)\). The softplus function is convex and we can express its epigraph \(t\geq\log(1+e^x)\) by combining two exponential cones. Note that
and therefore \(t\geq\log(1+e^x)\) is equivalent to the following set of conic constraints:
5.2.6 Log-sum-exp¶
We can generalize the previous example to a log-sum-exp (logarithm of sum of exponentials) expression
This is equivalent to the inequality
and so it can be modeled as follows:
5.2.7 Log-sum-inv¶
The following type of bound has applications in capacity optimization for wireless network design:
Since the logarithm is increasing, we can model this using a log-sum-exp and an exponential as:
Alternatively, one can also rewrite the original constraint in equivalent form:
and then model the right-hand side inequality using the technique from Sec. 3.2.7 (Harmonic mean). This approach requires only one exponential cone.
5.2.8 Log-sub-exp¶
Another bound we can model in a smimilar fashion could be called log-sub-exp:
It is equivalent to
which reduces log-sub-exp to Sec. 5.2.6 (Log-sum-exp). This is useful for modeling the hypograph of concave functions such as \(\log(e^x-1)\).
5.2.9 Arbitrary exponential¶
The inequality
where \(a_i\) are arbitrary positive constants, is of course equivalent to
and therefore to \((t, 1, \sum_ix_i\log{a_i})\in\EXP\).
5.2.10 Lambert W-function¶
The Lambert function \(W:[-e^{-1},+\infty)\to \R_+\) is the unique function satisfying the identity
It is the real branch of a more general function which appears in applications such as diode modeling. The \(W\) function is concave. Although there is no explicit analytic formula for \(W(x)\), the hypograph \(\{(x,t)~:~-e^{-1}\leq x,\ t\leq W(x)\}\) has an equivalent description:
which is valid because the function \(u\to u\log{u}\) is increasing on \(u\geq e^{-1}\), and so it can be modeled with two exponential cones (see (5.6)):
An alternative model valid only on \(x\geq 0\) can be obtained form the presentation
and that is \(x\geq t e^{u/t}\) together with \(u\geq t^2\), the latter modelled with a rotated quadratic cone.
5.2.11 Other simple sets¶
Here are a few more typical sets which can be expressed using the exponential and quadratic cones. The presentations should be self-explanatory; we leave the simple verifications to the reader.
Set |
Conic representation |
|---|---|
\(t\geq (\log{x})^2,\, 0< x\leq 1\) |
\((\frac12,t,u)\in\Qr^3,\, (x,1,u)\in\EXP,\, x\leq 1\) |
\(t\leq \log\log{x},\, x> 1\) |
\((u,1,t)\in\EXP,\, (x,1,u)\in\EXP\) |
\(t\geq (\log{x})^{-1},\, x>1\) |
\((u,t,\sqrt{2})\in\Qr^3,\, (x,1,u)\in\EXP\) |
\(t\leq\sqrt{\log{x}},\, x>1\) |
\((\frac12,u,t)\in\Qr^3,\, (x,1,u)\in\EXP\) |
\(t\leq\sqrt{x\log{x}},\, x>1\) |
\((x,u,\sqrt{2}t)\in\Qr^3,\, (x,1,u)\in\EXP\) |
\(t\leq\log(1-1/x),\, x>1\) |
\((x,u,\sqrt{2})\in\Qr^3,\, (1-u,1,t)\in\EXP\) |
\(t\geq\log(1+1/x),\, x>0\) |
\((x+1,u,\sqrt{2})\in\Qr^3,\, (1-u,1,-t)\in\EXP\) |
5.3 Geometric programming¶
Geometric optimization problems form a family of optimization problems with objective and constraints in special polynomial form. It is a rich class of problems solved by reformulating in logarithmic-exponential form, and thus a major area of applications for the exponential cone \(\EXP\). Geometric programming is used in circuit design, chemical engineering, mechanical engineering and finance, just to mention a few applications. We refer to [BKVH07] for a survey and extensive bibliography.
5.3.1 Definition and basic examples¶
A monomial is a real valued function of the form
where the exponents \(a_i\) are arbitrary real numbers and \(c>0\). A posynomial (positive polynomial) is a sum of monomials. Thus the difference between a posynomial and a standard notion of a multi-variate polynomial known from algebra or calculus is that (i) posynomials can have arbitrary exponents, not just integers, but (ii) they can only have positive coefficients.
For example, the following functions are monomials (in variables \(x,y,z\)):
and the following are examples of posynomials:
A geometric program (GP) is an optimization problem of the form
where \(f_0,\ldots,f_m\) are posynomials and \(x=(x_1,\ldots,x_n)\) is the variable vector.
A geometric program (5.14) can be modeled in exponential conic form by making a substitution
Under this substitution a monomial of the form (5.11) becomes
for \(a_\ast=(a_1,\ldots,a_n)\). Consequently, the optimization problem (5.14) takes an equivalent form
where \(a_{i,k}\in\R^n\) and \(c_{i,k}\in\R\) for all \(i,k\). These are now log-sum-exp constraints we already discussed in Sec. 5.2.6 (Log-sum-exp). In particular, the problem (5.15) is convex, as opposed to the posynomial formulation (5.14).
Example
We demonstrate this reduction on a simple example. Take the geometric problem
By substituting \(x=e^u\), \(y=e^v\), \(z=e^w\) we get
and using the log-sum-exp reduction from Sec. 5.2.6 (Log-sum-exp) we write an explicit conic problem:
Solving this problem yields \((x,y,z)\approx(3.14,2.43,1.32)\).
5.3.2 Generalized geometric models¶
In this section we briefly discuss more general types of constraints which can be modeled with geometric programs.
Monomials
If \(m(x)\) is a monomial then the constraint \(m(x)=c\) is equivalent to two posynomial inequalities \(m(x)c^{-1}\leq 1\) and \(m(x)^{-1}c\leq 1\), so it can be expressed in the language of geometric programs. In practice it should be added to the model (5.15) as a linear constraint
Monomial inequalities \(m(x)\leq c\) and \(m(x)\geq c\) should similarly be modeled as linear inequalities in the \(y_i\) variables.
In similar vein, if \(f(x)\) is a posynomial and \(m(x)\) is a monomial then \(f(x)\leq m(x)\) is still a posynomial inequality because it can be written as \(f(x)m(x)^{-1}\leq 1\).
It also means that we can add lower and upper variable bounds: \(0< c_1\leq x\leq c_2\) is equivalent to \(x^{-1}c_1\leq 1\) and \(c_2^{-1}x\leq 1\).
Products and positive powers
Expressions involving products and positive powers (possibly iterated) of posynomials can again be modeled with posynomials. For example, a constraint such as
can be replaced with
Other transformations and extensions
If \(f_1,f_2\) are already expressed by posynomials then \(\max\{f_1(x),f_2(x)\}\leq t\) is clearly equivalent to \(f_1(x)\leq t\) and \(f_2(x)\leq t\). Hence we can add the maximum operator to the list of building blocks for geometric programs.
If \(f,g\) are posynomials, \(m\) is a monomial and we know that \(m(x)\geq g(x)\) then the constraint \(\frac{f(x)}{m(x)-g(x)}\leq t\) is equivalent to \(t^{-1}f(x)m(x)^{-1}+g(x)m(x)^{-1}\leq 1\).
The objective function of a geometric program (5.14) can be extended to include other terms, for example:
\[\minimize\ f_0(x) + \sum_k\log{m_k(x)}\]where \(m_k(x)\) are monomials. After the change of variables \(x=e^y\) we get a slightly modified version of (5.15):
\[\begin{split}\begin{array}{lrcl} \minimize & t+b^Ty & & \\ \st & \sum_k\exp(a_{0,k,\ast}^Ty+\log{c_{0,k}}) & \leq & t, \\ & \log(\sum_k\exp(a_{i,k,\ast}^Ty+\log{c_{i,k}}))& \leq & 0,\ i=1,\ldots,m, \end{array}\end{split}\](note the lack of one logarithm) which can still be expressed with exponential cones.
5.3.3 Geometric programming case studies¶
Frobenius norm diagonal scaling
Suppose we have a matrix \(M\in\real^{n\times n}\) and we want to rescale the coordinate system using a diagonal matrix \(D=\Diag(d_1,\ldots,d_n)\) with \(d_i>0\). In the new basis the linear transformation given by \(M\) will now be described by the matrix \(DMD^{-1}=(d_iM_{ij}d_j^{-1})_{i,j}\). To choose \(D\) which leads to a “small” rescaling we can for example minimize the Frobenius norm
Minimizing the last sum is an example of a geometric program with variables \(d_i\) (and without constraints).
Maximum likelihood estimation
Geometric programs appear naturally in connection with maximum likelihood estimation of parameters of random distributions. Consider a simple example. Suppose we have two biased coins, with head probabilities \(p\) and \(2p\), respectively. We toss both coins and count the total number of heads. Given that, in the long run, we observed \(i\) heads \(n_i\) times for \(i=0,1,2\), estimate the value of \(p\).
The probability of obtaining the given outcome equals
and, up to constant factors, maximizing that expression is equivalent to solving the problem
or, as a geometric problem:
For example, if \((n_0,n_1,n_2)=(30,53,16)\) then the above problem solves with \(p = 0.29\).
An Olympiad problem
The 26th Vojtěch Jarník International Mathematical Competition, Ostrava 2016. Let \(a,b,c\) be positive real numbers with \(a+b+c=1\). Prove that
Using the tricks introduced in Sec. 5.3.2 (Generalized geometric models) we formulate this problem as a geometric program:
Unsurprisingly, the optimal value of this program is \(1728\), achieved for \((a,b,c,p,q,r)=\left(\frac13,\frac13,\frac13,12,12,12\right)\).
Power control and rate allocation in wireless networks
We consider a basic wireless network power control problem. In a wireless network with \(n\) logical transmitter-receiver pairs if the power output of transmitter \(j\) is \(p_j\) then the power received by receiver \(i\) is \(G_{ij}p_j\), where \(G_{ij}\) models path gain and fading effects. If the \(i\)-th receiver’s own noise is \(\sigma_i\) then the signal-to-interference-plus-noise (SINR) ratio of receiver \(i\) is given by
Maximizing the minimal SINR over all receivers (\(\max \min_i s_i\)), subject to bounded power output of the transmitters, is equivalent to the geometric program with variables \(p_1,\ldots,p_n,t\):
In the low-SNR regime the problem of system rate maximization is approximated by the problem of maximizing \(\sum_{i}\log{s_i}\), or equivalently minimizing \(\prod_i s_i^{-1}\). This is a geometric problem with variables \(p_i, s_i\):
For more information and examples see [BKVH07].
5.4 Exponential cone case studies¶
In this section we introduce some practical optimization problems where the exponential cone comes in handy.
5.4.1 Risk parity portfolio¶
Consider a simple version of the Markowitz portfolio optimization problem introduced in Sec. 3.3.3 (Markowitz portfolio optimization), where we simply ask to minimize the risk \(r(x)=\sqrt{x^T\Sigma x}\) of a fully-invested long-only portfolio:
where \(\Sigma\) is a symmetric positive definite covariance matrix. We can derive from the first-order optimality conditions that the solution to (5.19) satisfies \(\frac{\partial r}{\partial x_i}=\frac{\partial r}{\partial x_j}\) whenever \(x_i,x_j>0\), i.e. marginal risk contributions of positively invested assets are equal. In practice this often leads to concentrated portfolios, whereas it would benefit diversification to consider portfolios where all assets have the same total contribution to risk:
We call (5.20) the risk parity condition. It indeed models equal risk contribution from all the assets, because as one can easily check \(\frac{\partial r}{\partial x_i} = \frac{(\Sigma x)_i}{\sqrt{x^T\Sigma x}}\) and
Risk parity portfolios satisfying condition (5.20) can be found with an auxiliary optimization problem:
for any \(c>0\). More precisely, the gradient of the objective function in (5.21) is zero when \(\frac{\partial r}{\partial x_i}=c/x_i\) for all \(i\), implying the parity condition (5.20) holds. Since (5.20) is scale-invariant, we can rescale any solution of (5.21) and get a fully-invested risk parity portfolio with \(\sum_i x_i=1\).
The conic form of problem (5.21) is:
5.4.2 Entropy maximization¶
A general entropy maximization problem has the form
where \(\mathcal{I}\) defines additional constraints on the probability distribution \(p\) (these are known as prior information). In the absence of complete information about \(p\) the maximum entropy principle of Jaynes posits to choose the distribution which maximizes uncertainty, that is entropy, subject to what is known. Practitioners think of the solution to (5.23) as the most random or most conservative of distributions consistent with \(\mathcal{I}\).
Maximization of the entropy function \(H(x)=-x\log{x}\) was explained in Sec. 5.2 (Modeling with the exponential cone).
Often one has an a priori distribution \(q\), and one tries to minimize the distance between \(p\) and \(q\), while remaining consistent with \(\mathcal{I}\). In this case it is standard to minimize the Kullback-Leiber divergence
which leads to an optimization problem
5.4.3 Hitting time of a linear system¶
Consider a linear dynamical system
where we assume for simplicity that \(A=\Diag(a_1,\ldots,a_n)\) with \(a_i<0\) with initial condition \(\mathbf{x}(0)_i=x_i\). The resulting dynamical system \(\mathbf{x}(t)=\mathbf{x}(0)\exp(At)\) converges to \(0\) and one can ask, for instance, for the time it takes to approach the limit up to distance \(\varepsilon\). The resulting optimization problem is
with the following conic form, where the variables are \(t, q_1, \ldots,q_n\):
See Fig. 5.2 for an example. Other criteria for the target set of the trajectories are also possible. For example, polyhedral constraints
are also expressible in exponential conic form for starting points \(\mathbf{x}(0)\in\real_+^n\), since they correspond to log-sum-exp constraints of the form
For a robust version involving uncertainty on \(A\) and \(x(0)\) see [CS14].
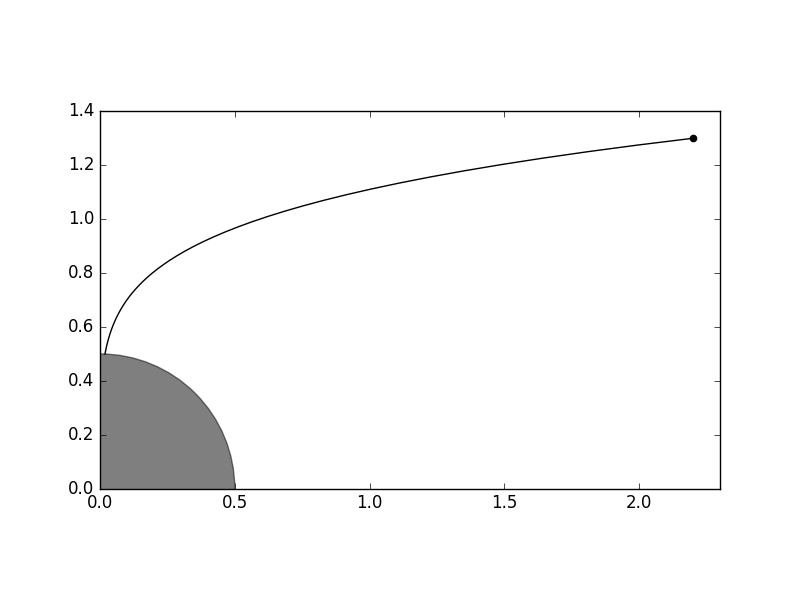
Fig. 5.2 With \(A=\Diag(-0.3, -0.06)\) and starting point \(x(0)=(2.2, 1.3)\) the trajectory reaches distance \(\varepsilon=0.5\) from origin at time \(t\approx 15.936\).¶
5.4.4 Logistic regression¶
Logistic regression is a technique of training a binary classifier. We are given a training set of examples \(x_1, \ldots, x_n \in\real^d\) together with labels \(y_i\in\{0,1\}\). The goal is to train a classifier capable of assigning new data points to either class 0 or 1. Specifically, the labels should be assigned by computing
and choosing label \(y=0\) if \(h_\theta(x)<\frac12\) and \(y=1\) for \(h_\theta(x)\geq \frac12\). Here \(h_\theta(x)\) is interpreted as the probability that \(x\) belongs to class 1. The optimal parameter vector \(\theta\) should be learned from the training set, so as to maximize the likelihood function:
By taking logarithms and adding regularization with respect to \(\theta\) we reach an unconstrained optimization problem
Problem (5.27) is convex, and can be more explicitly written as
involving softplus type constraints (see Sec. 5.2 (Modeling with the exponential cone)) and a quadratic cone. See Fig. 5.3 for an example.
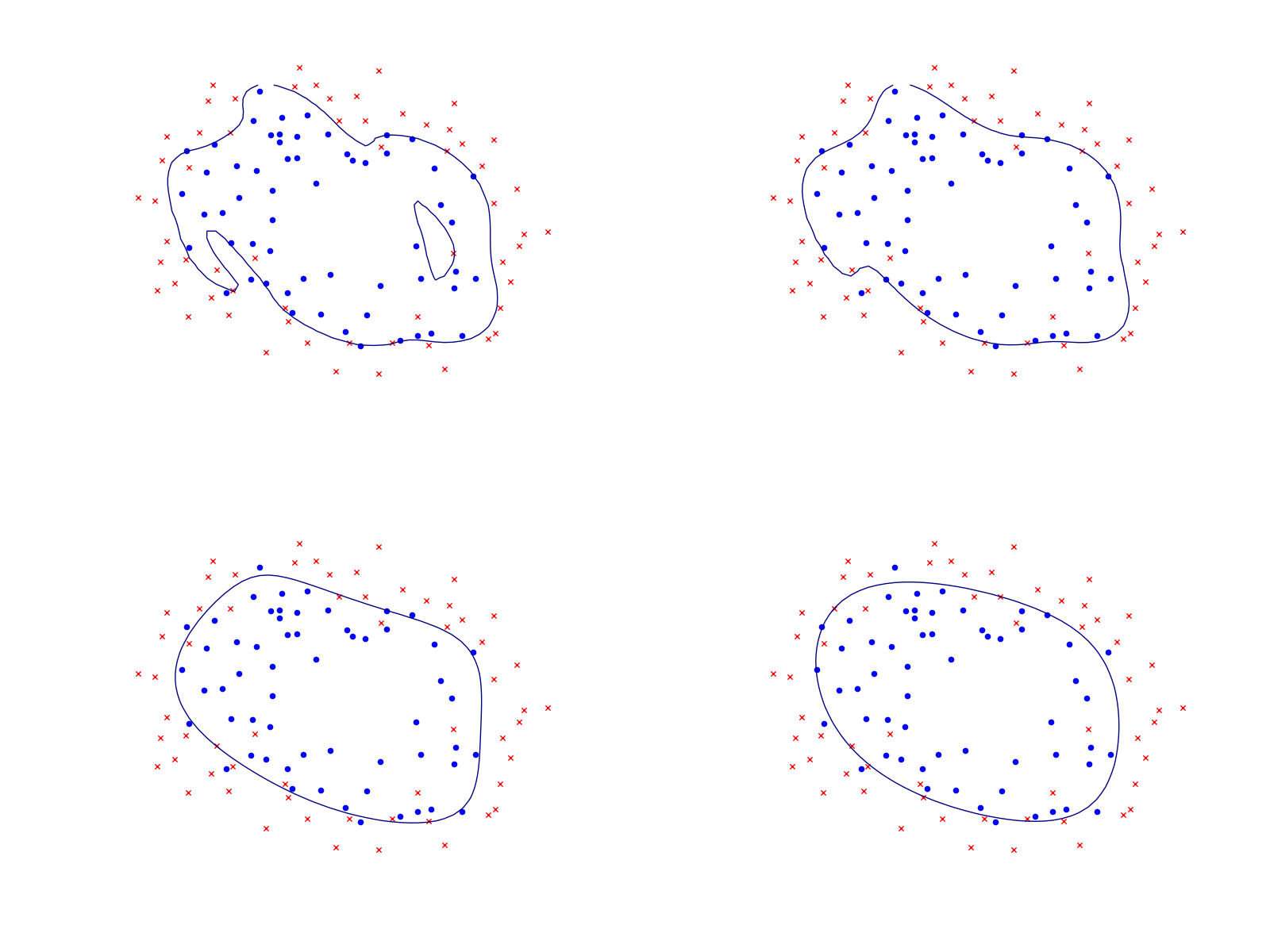
Fig. 5.3 Logistic regression example with none, medium and strong regularization (small, medium, large \(\lambda\)). The two-dimensional dataset was converted into a feature vector \(x\in\real^{28}\) using monomial coordinates of degrees at most 6. Without regularization we get obvious overfitting.¶
