
A tutorial to MOSEK 10
KTH Royal Institute of Technology
Stockholm, May 19th, 2022
Sven Wiese
www.mosek.com
LP in standard form:
Pro:
Therefore, we have powerful algorithms and software.
Con:

The classical nonlinear optimization problem:
Pro:
Con:
Is there a class of optimization problems that
Definition (Ben-Tal & Nemirovski, 2001): A good partial ordering of $\mathbb{R}^n$ is a vector relation that satisfies:
The coordinatewise ordering $$x\geq y \Longleftrightarrow x_i \geq y_i ~\forall i=1,\ldots,n$$
is an example, but not the only one!
The coordinatewise ordering leads to the cone $\mathbb{R}^n_+$.
In standard form:
where $\mathcal{K}$ is a (closed) pointed convex cone (with non-empty interior).
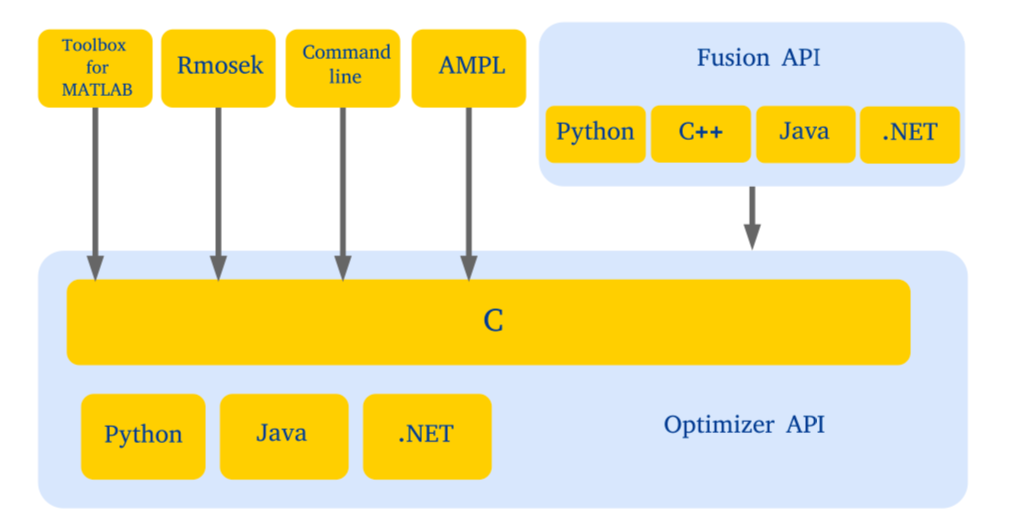
A software package/library for solving:
Current version is MOSEK 10, released March 2022.
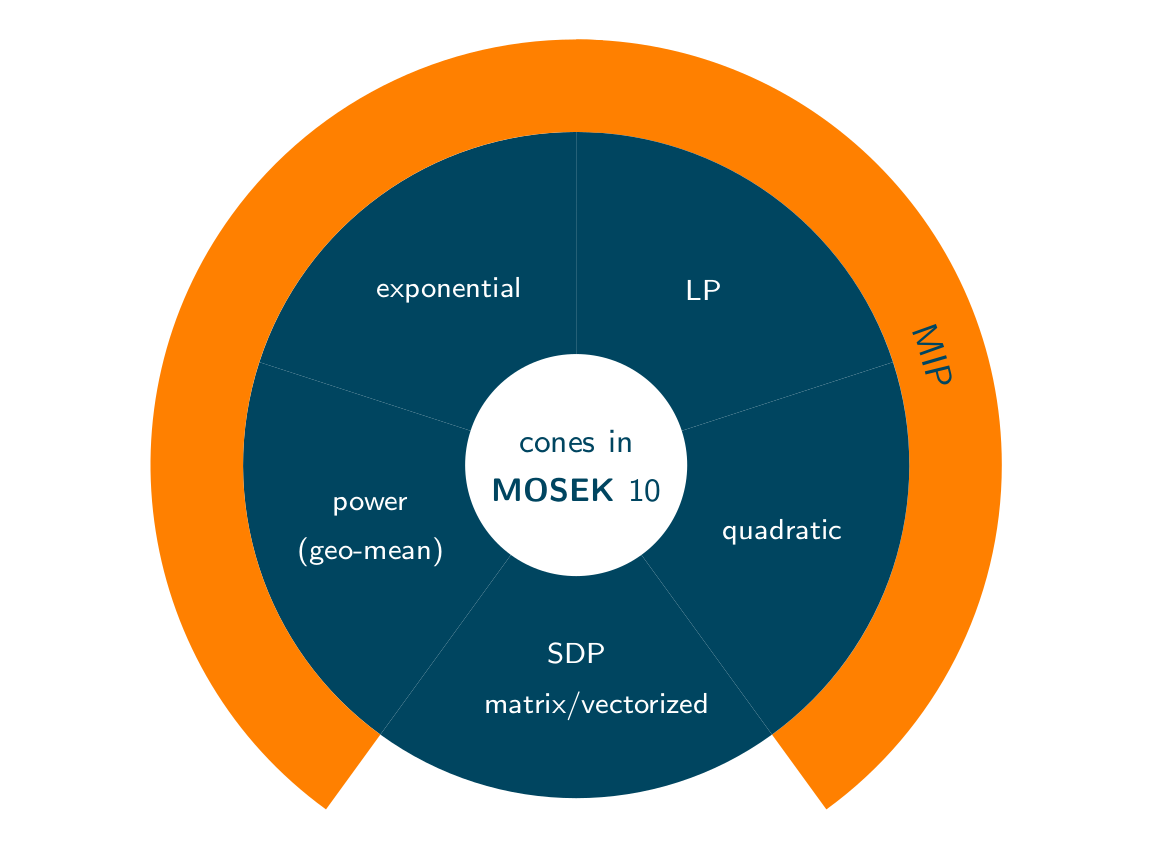
Continuous Optimmization folklore: "Almost all convex constraints that arise in practice are representable using these 5 cones."
More evidence: (Lubin et. al, 2016) show that all convex instances (333) in MINLPLIB2 are conic representable using only 4 of the above cones.
from mosek.fusion import *
print("Using Mosek version {ver}".format(ver=Model.getVersion()))
Using Mosek version 10.0.12
Solve a simple diet problem: combine servings of meals to meat min/max nutrient requirements.
| Corn | Milk | Bread | |
|---|---|---|---|
| Cost per serving | \$0.18 | \$0.23 | \$0.05 |
| Vitamin A | 107 | 500 | 0 |
| Calories | 72 | 121 | 65 |
| Max servings | - | 10 | 10 |
Vitamin A should stay between 2,000 and 2,250, calories between 5,000 and 50,000.
c, ux, lc, uc
([0.18, 0.23, 0.05], [inf, 10, 10], [5000, 2000], [50000, 2250])
np.reshape(A, (2,3))
array([[107, 500, 0],
[ 72, 121, 65]])
First create a model:
m = Model("diet-LP")
Add variables to it:
x = m.variable("x", 3, Domain.greaterThan(0.0))
Set the objective:
m.objective("obj", ObjectiveSense.Minimize, Expr.dot(c, x))
Add constraints on vitamin A and calorie intake:
m.constraint("vitaminA", Expr.dot(A[0], x), Domain.inRange(lc[0], uc[0]))
m.constraint("calories", Expr.dot(A[1], x), Domain.inRange(lc[1], uc[1]));
Set upper bounds on variables:
m.constraint(x.index(1), Domain.lessThan(ux[1]))
m.constraint(x.index(2), Domain.lessThan(ux[2]));
And solve:
m.solve()
# Always check the status
print(m.getPrimalSolutionStatus())
# Actual solution values
solvals = x.level()
print("Optimal x = {}".format(solvals))
print("Cost = {}".format(m.primalObjValue()))
SolutionStatus.Optimal Optimal x = [ 1.94444444 10. 10. ] Cost = 3.1499999999999995
Try some linear Algebra utils:
m.constraint("allIntakes", Expr.mul(A, x), Domain.inRange(lc, uc));
m.solve()
print(m.getPrimalSolutionStatus())
print("Cost = {}".format(m.primalObjValue()))
SolutionStatus.Optimal Cost = 3.1500000000000004
# clear the model
m.dispose()
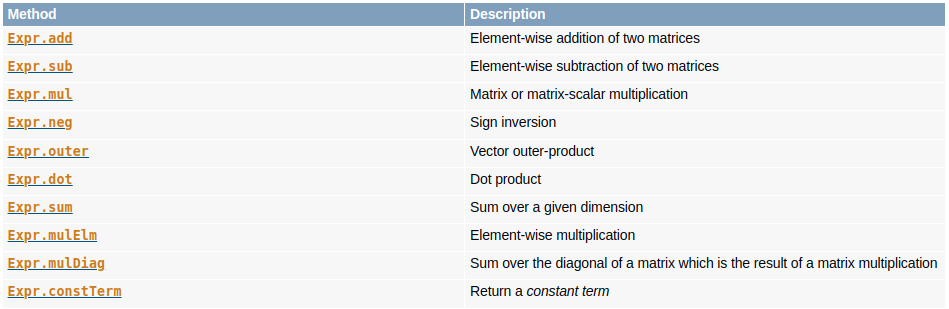
Linear operators available in Fusion's Expr class:
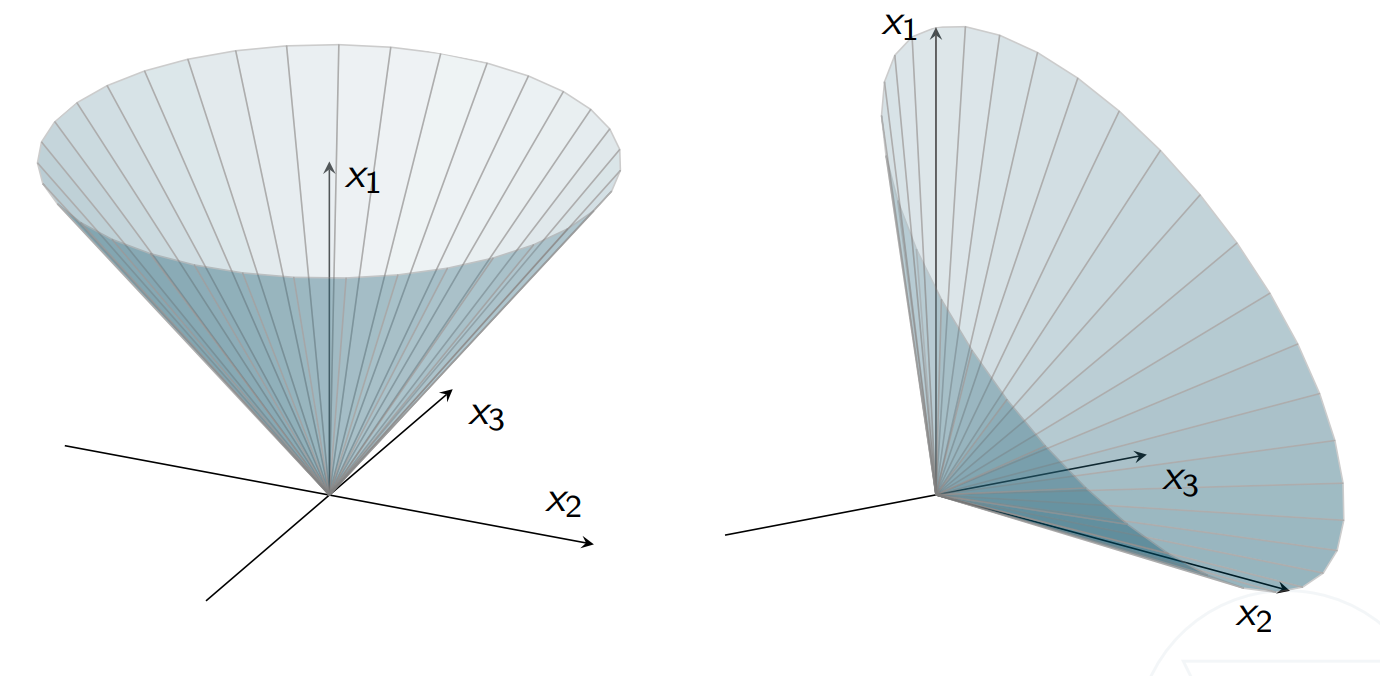
The quadratic cone family:
Are equivalent in the sense that $x\in\mathcal{Q}^n\Longleftrightarrow T_nx\in \mathcal{Q}^n_r$ with $T_n = $ $ \begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} & 0\\ 1/\sqrt{2} & -1/\sqrt{2} & 0\\ 0 & 0 & I_{n-2} \end{pmatrix}. $
Any convex (MI)QCQP can be cast in conic form!
Simplest form: given observations $y\in\mathbb{R}^n$ and features $X\in\mathbb{R}^{n\times d}$, solve
Put it in the conic framework - we need a bit of reformulation:
Remember: $\mathcal{Q}^n = \{ x\in \mathbb{R}^n \mid x_1 \geq \left( x_2^2 + \cdots + x_n^2 \right)^{1/2} = \|x_{2:n}\|_2 \}$
Solution:
plt.scatter(s,y);

n = len(s)
n
100
X = [[1,t,t**2,t**3] for t in s]
d = len(X[0])
d
4
m = Model("lse")
The regression coefficients and bound on the norm:
w = m.variable("w", d)
t = m.variable("t")
The quadratic cone constraint, note the (vertical) stacking:
r = Expr.sub(y, Expr.mul(X,w))
m.constraint(Expr.vstack(t, r), Domain.inQCone());
The objective:
m.objective(ObjectiveSense.Minimize, t)
m.solve()
print(m.getPrimalSolutionStatus())
SolutionStatus.Optimal
solvals = w.level()
ticks = np.linspace(0, 1, 100)
plt.scatter(s,y)
plt.plot(ticks, sum([solvals[i]*ticks**i for i in range(4)]), 'k', color='red');

# clear the model
m.dispose()
Portfolio optimization with market impact:
$x^t\Sigma x\leq \sigma^2$ is convex quadratic (easy to reformulate...), but how to model $t_i\geq x_i^{3/2}$?
For some constant $c$, together with $x\geq 0$,
implies $t_i \geq x_i^{3/2}$.
What's the value of $c$? Remember:
Solution:
# rqcone syntax
m.constraint(Expr.vstack(s, t, x), Domain.inRotatedQCone());
The LP and the quadratic cones are so-called symmetric cones: they are homogeneous and self-dual.
There are several nonsymmetric cones, exponential and power cones being two examples.
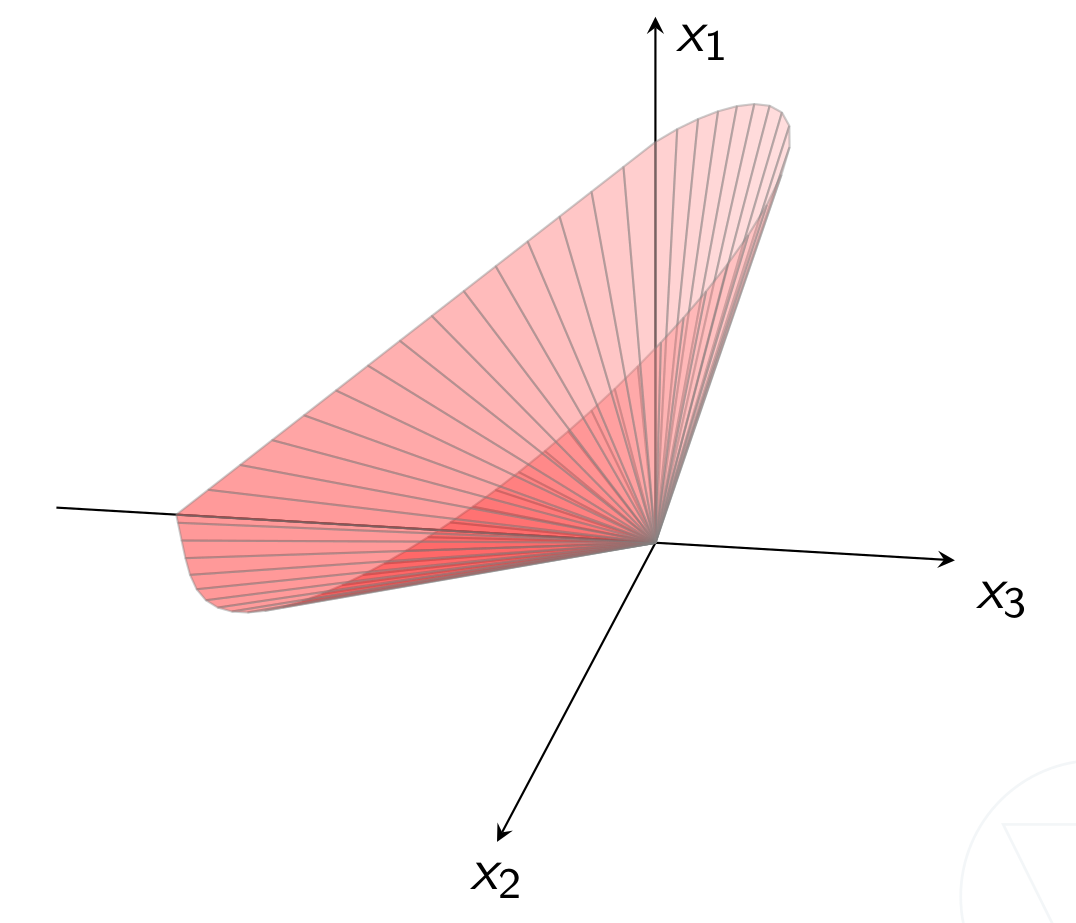
$n$-dimensional power cone:
with parameter $0 < \alpha < 1$.
More generally:
where $\beta_i = \alpha_i / (\sum_j\alpha_j)$.
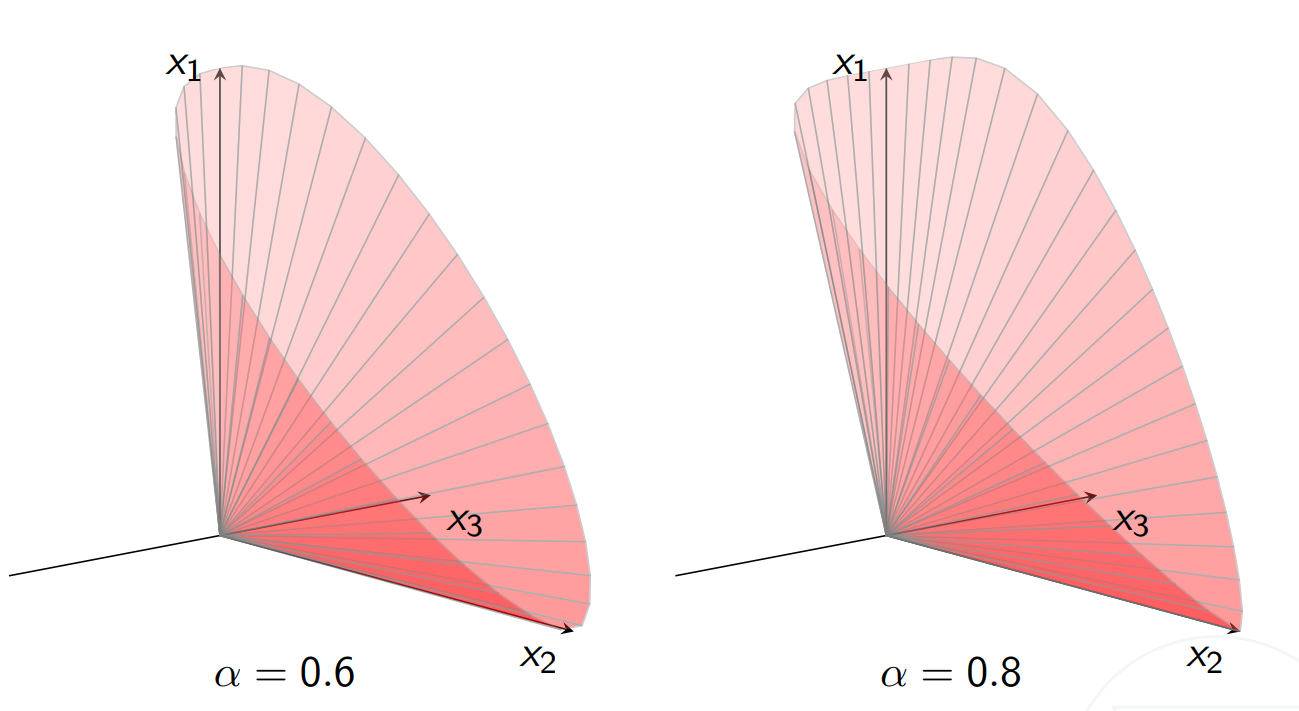
From above:
For $t \geq x^{3/2}$ use the power cone (instead of $(s,t,x), (x,1/8,s)\in \mathcal{Q}_r^3$...). Remember:
$$ \mathcal{P}^\alpha_3 = \{ x\in\mathbb{R}^3 \mid x_1^\alpha x_2^{(1-\alpha)} \geq | x_3|, \: x_1, x_2 \geq 0 \} $$Solution: $$t \geq |x|^{3/2} \Longleftrightarrow (t,1,x)\in\mathcal{P}_3^{(2/3,1/3)}.$$
nassets, sigma**2, mu
(8, 0.049999999999999996, [0.072, 0.1552, 0.1754, 0.0898, 0.429, 0.3929, 0.3217, 0.1838])
S
[[0.0946, 0.0374, 0.0349, 0.0348, 0.0542, 0.0368, 0.0321, 0.0327], [0.0374, 0.0775, 0.0387, 0.0367, 0.0382, 0.0363, 0.0356, 0.0342], [0.0349, 0.0387, 0.0624, 0.0336, 0.0395, 0.0369, 0.0338, 0.0243], [0.0348, 0.0367, 0.0336, 0.0682, 0.0402, 0.0335, 0.0436, 0.0371], [0.0542, 0.0382, 0.0395, 0.0402, 0.1724, 0.0789, 0.07, 0.0501], [0.0368, 0.0363, 0.0369, 0.0335, 0.0789, 0.0909, 0.0536, 0.0449], [0.0321, 0.0356, 0.0338, 0.0436, 0.07, 0.0536, 0.0965, 0.0442], [0.0327, 0.0342, 0.0243, 0.0371, 0.0501, 0.0449, 0.0442, 0.0816]]
m = Model("portfolio")
x = m.variable("x", nassets, Domain.greaterThan(0.0))
t = m.variable("t", nassets, Domain.unbounded())
Budget constraint $\sum_ix_i + a^Tt = 1$:
a = 0.01 # same weight for all assets
lhs = Expr.add(Expr.sum(x), Expr.mul(a, Expr.sum(t)))
m.constraint('budget', lhs, Domain.equalsTo(1));
One power cone constraint for each asset: $(t_i, 1, x_i) \in\mathcal{P}_3^{(2/3,1/3)}$
for i in range(nassets):
stack = Expr.hstack(Expr.hstack(t.index(i), 1), x.index(i))
m.constraint('market_' + str(i), stack, Domain.inPPowerCone(2/3))
# equivalent: Domain.inPPowerCone([2/3, 1/3])
Equivalent vectorization:
stack = Expr.hstack(Expr.hstack(t, Expr.constTerm(nassets, 1)), x)
m.constraint('market', stack, Domain.inPPowerCone(2/3));
The convex quadratic risk constraint $x^T\Sigma x \leq \sigma^2$:
G = np.linalg.cholesky(S)
print(np.max(np.abs(S - G @ G.T)))
1.3877787807814457e-17
m.constraint('risk', Expr.vstack(sigma, Expr.mul(G.T, x)), Domain.inQCone());
Set objective and solve:
m.objective('max-return', ObjectiveSense.Maximize, Expr.dot(mu, x))
m.solve()
print(m.getPrimalSolutionStatus())
solvals = x.level()
print("Optimal x = {}".format(solvals))
SolutionStatus.Optimal Optimal x = [1.03736753e-09 4.65082276e-09 4.82745337e-08 1.33397513e-09 9.53155147e-02 5.12895846e-01 1.93241136e-01 3.10401104e-09]
# clear the model
m.dispose()
The exponential cone: closure of the epigraph of the perspective of the exponential function:
or more explicitly
Exponentials:
Logarithm:
Entropy:
...
Given $n$ binary-labeled training-points $\{ (x_i, y_i) \}$ in $\mathbb{R}^{d+1}$, determine the classifier
Log-likelihood training:
How to model the softplus function $t\geq\log(1+\exp(z))$?
Hint: write as $e^{\ldots} + e^{\ldots} \leq 1$ and use 2 cone constraints as in
Solution: $$ u + v \leq 1, (u,1,z-t), (v,1,-t)\in\mathcal{K}_{exp}\implies e^{z-t} + e^{-t} \leq u + v \leq 1 $$
# 2d points p with labels
pos = np.where(labels == 1)
neg = np.where(labels == 0)
plt.scatter(p[pos,0], p[pos,1], marker='o', color='b')
plt.scatter(p[neg,0], p[neg,1], marker='x', color='r');

n = len(p)
n
118
Take monomials with some max degree $D$ as features: $$\theta^T x_i = \sum_{(a,b)~:~a+b\leq D}\theta_{(a,b)}p_{i1}^ap_{i2}^b$$
# map 2d data through all monomials of degree <= D
def mapFeature(p, D):
return np.array([(p[0]**a)*(p[1]**b) for a,b in itertools.product(range(D+1),
range(D+1)) if a+b<=D])
# store features of all observations in matrix P
P = np.array([mapFeature(a, 6) for a in p])
d = P.shape[1]
d
28
m = Model("log-reg")
theta = m.variable("theta", d)
t = m.variable("t", n)
# imposes t >= log(1 + exp(z)) with exponential cones
def softplus(m, t, z):
uv = m.variable(2)
m.constraint(Expr.sum(uv), Domain.lessThan(1))
stack = Expr.hstack(uv, Expr.constTerm(2, 1), Expr.vstack(Expr.sub(z,t), Expr.neg(t)))
m.constraint(stack, Domain.inPExpCone())
for i in range(n):
dot = Expr.dot(P[i], theta)
softplus(m, t.index(i), Expr.neg(dot) if labels[i] == 1 else dot)
m.objective(ObjectiveSense.Minimize, Expr.sum(t))
m.solve()
print(m.getPrimalSolutionStatus())
SolutionStatus.Optimal
u = np.linspace(-1, 1, 50)
v = np.linspace(-1, 1, 50)
w = np.zeros(shape=(len(u), len(v)))
for i in range(len(u)):
for j in range(len(v)):
w[i,j] = np.dot(mapFeature([u[i],v[j]], 6), theta.level())
plt.contour(u, v, w.T, [0])
plt.scatter(p[pos,0], p[pos,1], marker='o', color='b')
plt.scatter(p[neg,0], p[neg,1], marker='x', color='r');

The interior-point optimizer log:
m.setLogHandler(sys.stdout)
m.setSolverParam("logCutSecondOpt", 0)
m.solve()
Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 1 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.01 Problem Name : log-reg Objective sense : minimize Type : CONIC (conic optimization problem) Constraints : 118 Affine conic cons. : 236 Disjunctive cons. : 0 Cones : 0 Scalar variables : 383 Matrix variables : 0 Integer variables : 0 Optimizer - threads : 2 Optimizer - solved problem : the primal Optimizer - Constraints : 236 Optimizer - Cones : 237 Optimizer - Scalar variables : 737 conic : 737 Optimizer - Semi-definite variables: 0 scalarized : 0 Factor - setup time : 0.00 dense det. time : 0.00 Factor - ML order time : 0.00 GP order time : 0.00 Factor - nonzeros before factor : 7257 after factor : 7257 Factor - dense dim. : 0 flops : 9.65e+05 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 1.6e+00 1.3e+00 2.9e+02 0.00e+00 9.768493109e+01 -1.900040724e+02 1.0e+00 0.02 1 9.6e-01 7.8e-01 1.4e+02 6.66e-01 8.076910687e+01 -1.038898401e+02 6.0e-01 0.04 2 2.5e-01 2.1e-01 2.0e+01 7.36e-01 5.434773100e+01 1.360436002e-01 1.6e-01 0.05 3 7.9e-02 6.5e-02 3.8e+00 9.00e-01 4.401162601e+01 2.603100765e+01 5.0e-02 0.05 4 3.8e-02 3.1e-02 1.4e+00 8.77e-01 3.942023948e+01 3.017437637e+01 2.4e-02 0.05 5 1.4e-02 1.2e-02 3.6e-01 8.43e-01 3.611469451e+01 3.223559751e+01 9.1e-03 0.05 6 8.2e-03 6.7e-03 1.7e-01 7.17e-01 3.440135253e+01 3.187669380e+01 5.2e-03 0.06 7 3.7e-03 3.0e-03 5.9e-02 7.46e-01 3.311358979e+01 3.182690311e+01 2.3e-03 0.06 8 2.6e-03 2.1e-03 3.7e-02 7.42e-01 3.268713391e+01 3.172940015e+01 1.6e-03 0.06 9 1.3e-03 1.1e-03 1.5e-02 6.65e-01 3.193726078e+01 3.137467986e+01 8.2e-04 0.06 10 1.0e-03 8.4e-04 1.2e-02 4.78e-01 3.162516073e+01 3.111691947e+01 6.5e-04 0.07 11 5.4e-04 4.4e-04 6.8e-03 2.07e-01 3.057871447e+01 3.016602404e+01 3.4e-04 0.08 12 3.4e-04 2.8e-04 4.4e-03 8.17e-02 2.991192644e+01 2.957046429e+01 2.2e-04 0.08 13 2.3e-04 1.9e-04 3.0e-03 4.66e-02 2.933960273e+01 2.905411004e+01 1.5e-04 0.09 14 1.7e-04 1.4e-04 2.1e-03 9.36e-02 2.893584448e+01 2.869792152e+01 1.1e-04 0.09 15 1.0e-04 8.4e-05 1.2e-03 9.89e-02 2.818628233e+01 2.800468820e+01 6.5e-05 0.09 16 3.3e-05 2.7e-05 3.2e-04 2.27e-01 2.699551891e+01 2.691484907e+01 2.1e-05 0.09 17 1.1e-05 8.8e-06 7.3e-05 5.06e-01 2.634393282e+01 2.631216522e+01 6.8e-06 0.10 18 3.7e-06 3.0e-06 1.6e-05 7.54e-01 2.606416024e+01 2.605230274e+01 2.4e-06 0.10 19 8.1e-07 6.6e-07 1.7e-06 8.71e-01 2.591882345e+01 2.591612126e+01 5.1e-07 0.10 20 1.8e-07 1.5e-07 1.8e-07 9.72e-01 2.588558641e+01 2.588498745e+01 1.1e-07 0.11 21 5.1e-08 4.1e-08 2.8e-08 9.95e-01 2.587890900e+01 2.587873929e+01 3.2e-08 0.11 22 9.1e-09 7.2e-09 2.0e-09 9.99e-01 2.587672670e+01 2.587669725e+01 5.5e-09 0.11 23 4.0e-09 1.9e-09 2.9e-10 1.00e+00 2.587638933e+01 2.587638141e+01 1.5e-09 0.11 24 1.2e-09 3.3e-10 2.0e-11 1.00e+00 2.587628841e+01 2.587628706e+01 2.6e-10 0.12 25 1.4e-09 3.1e-10 1.9e-11 1.00e+00 2.587628742e+01 2.587628613e+01 2.4e-10 0.12 26 1.5e-09 2.5e-10 1.4e-11 1.00e+00 2.587628363e+01 2.587628258e+01 2.0e-10 0.12 27 1.3e-09 1.6e-10 6.8e-12 1.00e+00 2.587627742e+01 2.587627677e+01 1.2e-10 0.13 28 4.6e-10 3.3e-11 6.4e-13 1.00e+00 2.587626940e+01 2.587626927e+01 2.5e-11 0.13 Optimizer terminated. Time: 0.14 Interior-point solution summary Problem status : PRIMAL_AND_DUAL_FEASIBLE Solution status : OPTIMAL Primal. obj: 2.5876269399e+01 nrm: 4e+03 Viol. con: 8e-09 var: 0e+00 acc: 7e-10 Dual. obj: 2.5876269265e+01 nrm: 1e+00 Viol. con: 0e+00 var: 5e-09 acc: 0e+00
The interior-point optimizer solves the so-called homogeneous model, and converges towards
at the same time!
... or otherwise provides certificates of primal or dual infeasibility (modulo ill-posedness).
MOSEK allows integer variables together with all cone types seen until now.
Example: Logistic regression problem as above with feature selection:
Modeled with bigM-constraints:
z = m.variable(d, Domain.binary())
bigM = 10
m.constraint(Expr.add(theta, Expr.mul(bigM, z)), Domain.greaterThan(0.0))
m.constraint(Expr.add(Expr.neg(theta), Expr.mul(bigM, z)), Domain.greaterThan(0.0))
F = 1.0
m.updateObjective(Expr.mul(F, Expr.sum(z)), z)
m.solve()
print(m.getPrimalSolutionStatus())
Optimizer started. Mixed integer optimizer started. Threads used: 2 Presolve started. Presolve terminated. Time = 0.02, probing time = 0.00 Presolved problem: 764 variables, 292 constraints, 3862 non-zeros Presolved problem: 0 general integer, 28 binary, 736 continuous Presolved problem: 236 cones Clique table size: 0 BRANCHES RELAXS ACT_NDS DEPTH BEST_INT_OBJ BEST_RELAX_OBJ REL_GAP(%) TIME 0 1 1 0 5.3697611392e+01 4.4304292152e+01 17.49 0.1 0 1 1 0 5.1548852184e+01 4.4304292152e+01 14.05 0.4 Cut generation started. 0 1 1 0 5.1548852184e+01 4.4304292035e+01 14.05 0.7 0 2 1 0 5.1548852184e+01 4.4469465482e+01 13.73 0.8 Cut generation terminated. Time = 0.24 7 12 8 4 5.0897036500e+01 4.4487982131e+01 12.59 1.3 15 20 14 5 4.9813496885e+01 4.5353208028e+01 8.95 1.5 29 34 24 6 4.9813496885e+01 4.5353208028e+01 8.95 1.7 53 58 40 9 4.9400237093e+01 4.6006341562e+01 6.87 2.1 93 98 64 12 4.8587817063e+01 4.6458428636e+01 4.38 2.7 139 143 88 15 4.8179334094e+01 4.6657335927e+01 3.16 3.4 192 189 87 8 4.7152850707e+01 4.7152850707e+01 0.00e+00 4.0 An optimal solution satisfying the relative gap tolerance of 1.00e-02(%) has been located. The relative gap is 0.00e+00(%). An optimal solution satisfying the absolute gap tolerance of 0.00e+00 has been located. The absolute gap is 0.00e+00. Objective of best integer solution : 4.715285070663e+01 Best objective bound : 4.715285070663e+01 Initial feasible solution objective: Undefined Construct solution objective : Not employed User objective cut value : Not employed Number of cuts generated : 2 Number of CMIR cuts : 2 Number of branches : 192 Number of relaxations solved : 189 Number of interior point iterations: 4508 Number of simplex iterations : 0 Time spend presolving the root : 0.02 Time spend optimizing the root : 0.03 Mixed integer optimizer terminated. Time: 4.00 Optimizer terminated. Time: 4.01 Integer solution solution summary Problem status : PRIMAL_FEASIBLE Solution status : INTEGER_OPTIMAL Primal. obj: 4.7152850707e+01 nrm: 2e+01 Viol. con: 6e-09 var: 0e+00 acc: 8e-09 itg: 3e-07 SolutionStatus.Optimal
print("Selected {s} out of {t} features.".format(s = int(sum(z.level())), t = z.getSize()))
u = np.linspace(-1, 1, 50)
v = np.linspace(-1, 1, 50)
w = np.zeros(shape=(len(u), len(v)))
for i in range(len(u)):
for j in range(len(v)):
w[i,j] = np.dot(mapFeature([u[i],v[j]], 6), theta.level())
plt.contour(u, v, w.T, [0])
plt.scatter(p[pos,0], p[pos,1], marker='o', color='b')
plt.scatter(p[neg,0], p[neg,1], marker='x', color='r');
Selected 7 out of 28 features.

The PSD cone can be defined in matrix space $\mathbb{R}^{n\times n}$:
If desired one may also work in vector space $\mathbb{R}^{n(n+1)/2}$:
with $ \text{svec}(X) := (X_{11}, \sqrt{2}X_{21}, \ldots, \sqrt{2}X_{n1}, X_{22}, \sqrt{2}X_{32}, \ldots, X_{nn})^T $
Note that $\Vert X\Vert_F = \Vert \text{svec}(X)\Vert_2$.
Let $C\in\mathbb{S}^n$ and assume we want to find its nearest correlation matrix
i.e. $X^* = \min_{X\in\mathcal{C}}\Vert C - X\Vert_F.$
n = np.shape(C)[0]
n, C
(5, [[0.0, 0.5, -0.1, -0.2, 0.5], [0.5, 1.25, -0.05, -0.1, 0.25], [-0.1, -0.05, 0.51, 0.02, -0.05], [-0.2, -0.1, 0.02, 0.54, -0.1], [0.5, 0.25, -0.05, -0.1, 1.25]])
def svec(X):
N = X.getShape()[0]
msubi = range(N * (N + 1) // 2)
msubj = [i * N + j for i in range(N) for j in range(i + 1)]
mcof = [2.0**0.5 if i !=
j else 1.0 for i in range(N) for j in range(i + 1)]
S = Matrix.sparse(N * (N + 1) // 2, N * N, msubi, msubj, mcof)
return Expr.mul(S, Expr.flatten(X))
m = Model("corr-mat")
# use a matrix variable!
X = m.variable("X", [n,n], Domain.inPSDCone(n))
t = m.variable("t")
# (t, vec (C-X)) \in Q
m.constraint("norm", Expr.vstack(t, svec(Expr.sub(C, X))), Domain.inQCone());
# diag(X) = e
m.constraint("diag", X.diag(), Domain.equalsTo(1.0));
m.objective(ObjectiveSense.Minimize, t)
m.solve()
print(m.getPrimalSolutionStatus())
SolutionStatus.Optimal
X.level(), C
(array([ 1. , 0.50000348, -0.10000045, -0.20000096, 0.50000348,
0.50000348, 1. , -0.04999996, -0.09999996, 0.25000085,
-0.10000045, -0.04999996, 1. , 0.01999993, -0.04999996,
-0.20000096, -0.09999996, 0.01999993, 1. , -0.09999996,
0.50000348, 0.25000085, -0.04999996, -0.09999996, 1. ]),
[[0.0, 0.5, -0.1, -0.2, 0.5],
[0.5, 1.25, -0.05, -0.1, 0.25],
[-0.1, -0.05, 0.51, 0.02, -0.05],
[-0.2, -0.1, 0.02, 0.54, -0.1],
[0.5, 0.25, -0.05, -0.1, 1.25]])
Also the SDP cone is a symmetric cone!
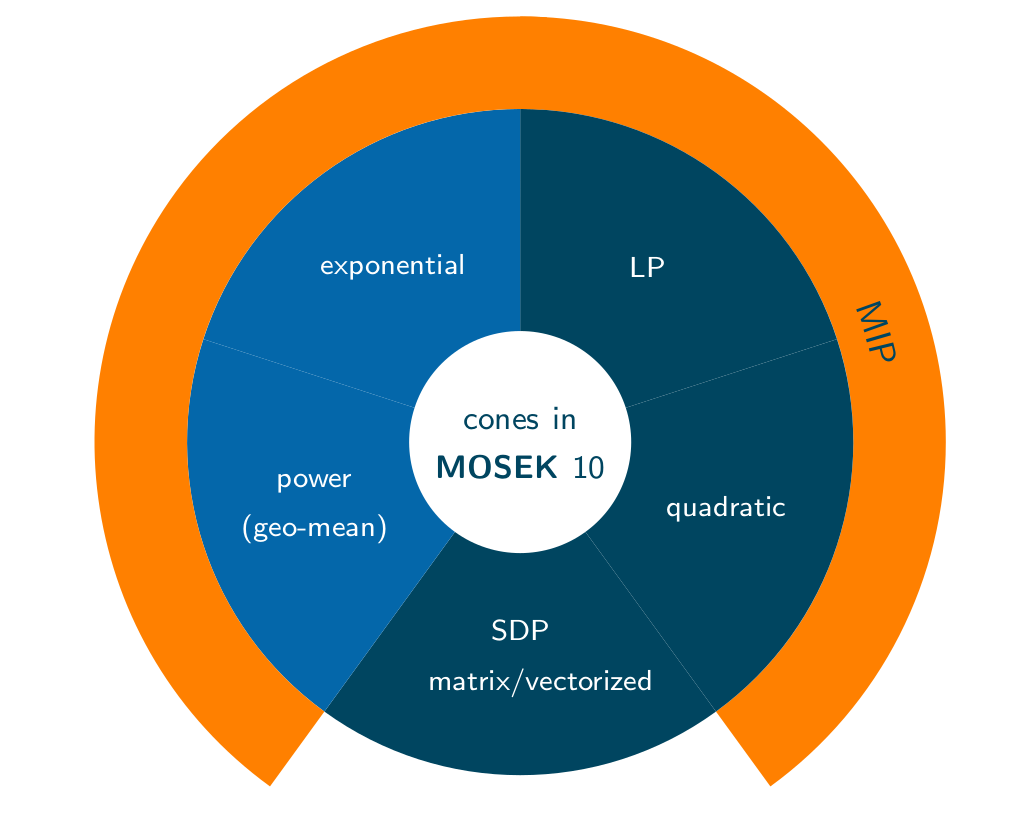
"Exotic" cones:
But for every new cone, questions arise:
Remember the folklore: "Almost all convex constraints that arise in practice are representable using these 5 cones."
# x_i = 2.5 for any one of i = 0,1,2,3
m.disjunction([DJC.term(x.index(i), Domain.equalsTo(2.5)) for i in range(4)])
dualsolvals = x.dual()
A. Ben-Tal & A. Nemirovski: Lectures on Modern Convex Optimization, SIAM (2001).
### $\texttt{www.mosek.com}\longrightarrow$ Documentation