11.2 Logistic regression¶
Logistic regression is an example of a binary classifier, where the output takes one two values 0 or 1 for each data point. We call the two values classes.
Formulation as an optimization problem
Define the sigmoid function
Next, given an observation \(x\in\real^d\) and a weights \(\theta\in\real^d\) we set
The weights vector \(\theta\) is part of the setup of the classifier. The expression \(h_\theta(x)\) is interpreted as the probability that \(x\) belongs to class 1. When asked to classify \(x\) the returned answer is
When training a logistic regression algorithm we are given a sequence of training examples \(x_i\), each labelled with its class \(y_i\in \{0,1\}\) and we seek to find the weights \(\theta\) which maximize the likelihood function
Of course every single \(y_i\) equals 0 or 1, so just one factor appears in the product for each training data point. By taking logarithms we can define the logistic loss function:
The training problem with regularization (a standard technique to prevent overfitting) is now equivalent to
This can equivalently be phrased as
Implementation
As can be seen from (11.13) the key point is to implement the softplus bound \(t\geq \log(1+e^u)\), which is the simplest example of a log-sum-exp constraint for two terms. Here \(t\) is a scalar variable and \(u\) will be the affine expression of the form \(\pm \theta^Tx_i\). This is equivalent to
and further to
This formulation can be entered using affine conic constraints (see Sec. 6.2 (From Linear to Conic Optimization)).
# Adds ACCs for t_i >= log ( 1 + exp((1-2*y[i]) * theta' * X[i]) )
# Adds auxiliary variables, AFE rows and constraints
def softplus(task, d, n, theta, t, X, y):
nvar = task.getnumvar()
ncon = task.getnumcon()
nafe = task.getnumafe()
task.appendvars(2*n) # z1, z2
task.appendcons(n) # z1 + z2 = 1
task.appendafes(4*n) #theta * X[i] - t[i], -t[i], z1[i], z2[i]
z1, z2 = nvar, nvar+n
zcon = ncon
thetaafe, tafe, z1afe, z2afe = nafe, nafe+n, nafe+2*n, nafe+3*n
for i in range(n):
task.putvarname(z1+i,f"z1[{i}]")
task.putvarname(z2+i,f"z2[{i}]")
# z1 + z2 = 1
task.putaijlist(range(zcon, zcon+n), range(z1, z1+n), [1]*n)
task.putaijlist(range(zcon, zcon+n), range(z2, z2+n), [1]*n)
task.putconboundsliceconst(zcon, zcon+n, boundkey.fx, 1, 1)
task.putvarboundsliceconst(nvar, nvar+2*n, boundkey.fr, -inf, inf)
# Affine conic expressions
afeidx, varidx, fval = [], [], []
## Thetas
for i in range(n):
for j in range(d):
afeidx.append(thetaafe + i)
varidx.append(theta + j)
fval.append(-X[i][j] if y[i]==1 else X[i][j])
# -t[i]
afeidx.extend([thetaafe + i for i in range(n)] + [tafe + i for i in range(n)])
varidx.extend([t + i for i in range(n)] + [t + i for i in range(n)])
fval.extend([-1.0]*(2*n))
# z1, z2
afeidx.extend([z1afe + i for i in range(n)] + [z2afe + i for i in range(n)])
varidx.extend([z1 + i for i in range(n)] + [z2 + i for i in range(n)])
fval.extend([1.0]*(2*n))
# Add the expressions
task.putafefentrylist(afeidx, varidx, fval)
# Add a single row with the constant expression "1.0"
oneafe = task.getnumafe()
task.appendafes(1)
task.putafeg(oneafe, 1.0)
# Add an exponential cone domain
expdomain = task.appendprimalexpconedomain()
# Conic constraints
acci = task.getnumacc()
for i in range(n):
task.appendacc(expdomain, [z1afe+i, oneafe, thetaafe+i], None)
task.appendacc(expdomain, [z2afe+i, oneafe, tafe+i], None)
task.putaccname(acci, f"z1:theta[{i}]")
task.putaccname(acci+1,f"z2:t[{i}]")
acci += 2
Once we have this subroutine, it is easy to implement a function that builds the regularized loss function model (11.13).
# Model logistic regression (regularized with full 2-norm of theta)
# X - n x d matrix of data points
# y - length n vector classifying training points
# lamb - regularization parameter
def logisticRegression(X, y, lamb=1.0):
n, d = int(X.shape[0]), int(X.shape[1]) # num samples, dimension
with Task() as task:
# Variables [r; theta; t; u]
nvar = 1+d+2*n
task.appendvars(nvar)
task.putvarboundsliceconst(0, nvar, boundkey.fr, -inf, inf)
r, theta, t = 0, 1, 1+d
task.putvarname(r,"r");
for j in range(d): task.putvarname(theta+j,f"theta[{j}]");
for j in range(n): task.putvarname(t+j,f"t[{j}]");
# Objective lambda*r + sum(t)
task.putobjsense(objsense.minimize)
task.putcj(r, lamb)
task.putclist(range(t, t+n), [1.0]*n)
# Softplus function constraints
softplus(task, d, n, theta, t, X, y);
# Regularization
# Append a sequence of linear expressions (r, theta) to F
numafe = task.getnumafe()
task.appendafes(1+d)
task.putafefentry(numafe, r, 1.0)
for i in range(d):
task.putafefentry(numafe + i + 1, theta + i, 1.0)
# Add the constraint
task.appendaccseq(task.appendquadraticconedomain(1+d), numafe, None)
# Solution
task.writedata('logistic.ptf')
task.optimize()
xx = task.getxxslice(soltype.itr, theta, theta+d)
return xx
Example: 2D dataset fitting
In the next figure we apply logistic regression to the training set of 2D points taken from the example ex2data2.txt . The two-dimensional dataset was converted into a feature vector \(x\in\real^{28}\) using monomial coordinates of degrees at most 6.
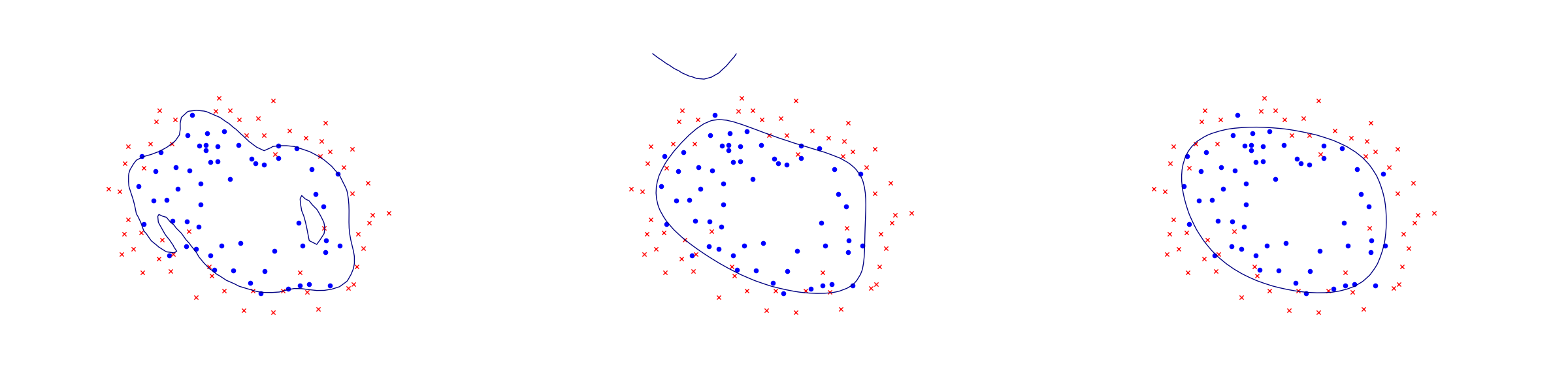
Fig. 11.2 Logistic regression example with none, medium and strong regularization (small, medium, large \(\lambda\)). Without regularization we get obvious overfitting.¶
